


nec_000
-
מספר הודעות
5377 -
הצטרפות
-
ביקר לאחרונה
-
Days Won
81
הודעות שנפתחו על-ידי nec_000
-
-
חדשות מעניינות על AMD וגם נוידיאה, את חלקן מכירים חלקן טרם, הכל קשור להכל ול- RDNA2 כמובן,
אז מרכז הכל פה. לא מצאתי שרשור יותר מתאים:
-
 1
1
-
-
- תגובה פופולרית
- תגובה פופולרית
ציטוט של af db creidאני משער שאמור להיות "לך"
")
צודק. תראה את השעה אני כבר חצי מסטול...
DB שלם שנכנס בRAM? לא נראה לי
בנוסף, הרבה פעמים עובדים על הDB דרך הרשת, כך שבכל מקרה צוואר הבקבוק הוא אינו הRAM ואפילו לא הדיסק.
כן, יש מצבים שה- DB כולו נכנס ב-RAM, ואז השרת עובד הלכה למעשה עם %100 DB in cache. אצלי באחת
המערכות זה כך. רכשנו שרת סימפליויטי עם שלושת רבעי טרה זכרון, הכל נכנס ועוד נשאר עודף. הוא כולו מבוסס flash
בנוסף, כך שבכלל. אה ו- 88 ליבות.
אכן הרשת היא צוואר הבקבוק, בוודאי ביחס לביצועים כשל מפלצת כשלנו שתארתי זה עתה.
לכן מי שרוצה ביצועים יעשה נבון אילו יעבוד ישירות על המכונה ויריץ עליה את הגזירות או הדוחות.
כל מכונה כזו עלתה לנו כ- 100K$ באוקטובר 2018.
האמת סכום קטן לעומת מה שהיא מסוגלת לתת.
-
 1
1
-
 1
1
-
מענה ל- no one.
מעתיק את הטקסט שלך בשחור ומתייחס בטקסט כחול:
1.אם הבנתי נכון הרעיון הוא שעל הקאש ישבו 2 תמונות, אחת שעוברת בניה\עיבוד עם כל נושא הפוליגונים, ועוד תמונה שלמה.
אם תמונה ברזולוציית 4k צורכת נפח זיכרון של 32MB אז 2 תמונות צורכות 64MB, לא הבנתי למה הוצרכנו להמתין לליטוגרפיה שתאפשר 128MB של קאש, שהרי ע"פ ההסבר הנ"ל דיי ב64MB, לאן התפספסו לי בהסבר עוד 64?
ההסבר שהבאתי הוא מאד מתומצת (בכוונה) יש כמה וכמה מרכיבים שצריכים לשבת ב- cache בו זמנית. בכללם כל
הוקטורים, הקודקודים, הפוליגונים המחושבים, הטקסטורה (אחת לפחות כמובן), נתוני z buffering לחסכון בשכבות
הרנדור, נתוני mip mapping, רכיבי הארה, ועוד. יש היום גם דחיסות מידע שיתכן, וצריכות כלי עזר בצד לסייע
לפרוש ולדחוס וכדומה. עם השנים נוספו גם עוד טכנולוגיות שזקן כמותי צריך לקרוא ולהשלים אותם.
ובנוסף לשמור מקום לחישובי ביניים כשטח עבודה... בקיצור ערב רב של נושאים. זה מורכב מאד העסק הזה. ולכן, אם
פריים בודד בגודל 4K שותה כבר לבדו רבע מכל ה- cache, זה כבר כבד מאד במה שזה מותיר ליתר הצרכים. חסר לנו
ה- stack המלא של AMD, איך בדיוק אלגוריתמית היא מבצעת מה, מה שומרת ב cache, כמה נפח צורך כל דבר, ומה
סדר הפעולות וזריקת החומר החוצה מה- cache כדי לפנות מקום למשהו אחר.
וזה משהו שאינו נגיש לנו כי הוא סוד שלא יגלו אותו. אז לא ניתן לבצע חישוב משלנו, איך בדיוק הם עושים את זה. ככל
המסתמן, הם מסתדרים עם cache של 128MB וזה עושה את העבודה היטב. האם 64MB יכול להספיק איכשהו? יתכן.
נהיה הרבה יותר חכמים אחרי השקת Navi22 שהוא שבב חצי גודל עם רק 40cu. אנו נראה באמצעותו, האם הסתפקו
ב- 64MB cache, או שנאלצו לשים גם 128MB ואז נלמד מזה משהו.
2.ידוע באופן כללי שקצב תעבורת הנתונים של רכיבי חומרה שמאחסנים נתונים מדורג באופן שהנמוך ברשימה מהיר ביותר :
דיסק קשיח\SSD
RAM
ואז רמות הקאש השונות במעבד L1\L2\L3 ובין כל רמה לרמה, הנפח קטן, הזיכרון קרוב יותר למעבד ומהיר יותר.
מסיבות שעדיין לא נתקלתי בביאור להן, CPU (בסגמט הגבוה) עובדים בסדר גודל של 5GHZ, בעוד שGPU עובדים בסדר גודל של 2GHZ (אני מודע לכך שהם שונים באופנים רבים ביעודם\מבניהם) ומכאן מגיעות שתי תתי שאלות:
ההבדל בתדרי העבודה נובע מהצפיפות הטרנזיטורית ואורך מסלול האות.
ה- pipe line במעבד גראפי הוא פיסית מאד ארוך בגלל שהוא מחזיק אלפי ליבות, שאין ברירה, אלא לפרוס אותן על
שטח נרחב כדי שכולן יכנסו, וכתוצאה מכך, מסלול האות לכל אחת מהם יוצא מקצה לקצה לא קצר. בגלל הריחוק
הגאוגראפי. הגדלת מסלול אות מקטינה את פוטנציאל תדר הריצה.
הסיבה השניה היא אופי העבודה, במעבד גראפי אלפי ליבות שיורות במקביל יחדיו, הצריכה האנרטית חלקי שטח גדולה
יותר משמעותית ממעבד CPU ומשכך כמות החום הנדרשת לפליטה ליחידה שטח, היא כזו, שמגבילה את כושר הנידוף, ולכן את התדר שניתן להגיע אליו מבלי לשרוף את המעבד.
עוד כוון שמרמז לנו, מעבדים היום זה בהכי חדשים, ריזן, כ- 4 מיליארד טרנזיסטורים למעבד. מצד שני מעבד גראפי כמו
שני החדשים שהושקו GA102 ו- NAVI21, הם 28 ו- 26 מיליארד טרניזטורים. די מהר מבינים פה את יחסי הכוחות
ועד כמה GPU זו מפלצת, שגדולה משמעותית בעומס שלה מאשר CPU וזה משפיע על התדר גם.
שלוב הסיבות לעיל, מאלץ מעבד גראפי לעבוד בתדרים נמוכים יותר משל CPU.
א.מדוע רוחב פס לזיכרון (בכלליות בשלל הכרטיסים הקיימים, ובפרט בחידוש של AMD שעכשיו הזיכרון גם ברמת הקאש) היא בסדר גודל נמוך מאוד יחסית, MBPS1612 ע"פ השקף הנ"ל, לקצב תעבורת נתונים של כונן NVMe ממוצע, בעוד שזה האחרון אמור להיות איטי יותר מאחר והוא לא נמצא ברמת הקאש של המעבד. מה כאן התפספס לי?
שאני טעיתי במאמר,
כתבתי בכל המקומות בטעות סופר את הערך Mbyte כשהיה צריך להיות Gbyte. ובזכות שאלתך, נכנסתי ותקנתי
במאמר (תודה לך על כך). ולכן אחדד כאן, שמהירות רוחב הפס זכרון איפה של 256bit באמצעות GDDR 6 היא
512Gbyte לשניה. הרוחב פס המשולב של ה cache וה- VRAM יוצא כ- 1600Gbyte לשניה.
ובהשוואה אליהן:
רוחב פס זכרון Ram במחשב מודרני המשתמש בזכרון DDR4 הוא סביבות 30-50Gbyte. ורוחב פס של כונן SSD מסוג
NVme הוא מסדר גודל של 1.5-3Gbyte בלבד.
ב.אם מה שחונק את קצב עבודת ה GPU הוא מהירות הזיכרון (שבכל מקרה מהירה הרבה יותר מRAM רגיל) בעוד שהוא עצמו עובד בחצי מהמהירות של הCPU, למה בCPU רגיל מהירות הזיכרון לא מגבילה יחסית את עבודת הCPU, והיא שלעצמה דיי זניחה בתוספת הביצועים (לצורך המחשה ההבדל בין MHZ3000 ל MHZ4000) בעוד שבGPU היא צוואר הבקבוק. לא ראינו שבמעבדים אצים לסגל DDR5 כדי לזנק בביצועים, אלא רק מנסים להגביר את תדר העבודה (כמובן גם הוספת ליבות ושיפור ומזעור הארכיטקטורה וכו'). איפה מונח ההבדל היסודי שגורם למהירות הזיכרון (שגם ככה מהיר) בGPU לבקבק את העסק, בעוד שהליבה איטית מאוד יחסית לCPU?
קיבלתי רושם דיי פרדוקסאלי בגורם המאט בין הCPU לGPU
מעבד מסתפק בכמות זכרון מטמון קטנה על מנת להגיע למצב, שרוב הדרישות שלו לקריאה כתיבה בקוד שכתוב
מתאים, מוצאות hit מול הזכרון מטמון שלו ולא miss (אירוע שיאלצו לרדת ל- RAM). מנגד מעבד גראפי (ואנחנו
מדברים עדיין על העידן שהוא טרום cache) צריך לכל פעולה שלו לרדת על עד ל- VRAM ולמעשה כל קריאה וכתיבה
שלו נעשית ישירות מול VRAM.
נמצא שאם מגדילים את מהירות ה- RAM ביצועי מעבדי CPU משתפרים בישומים מאד ספציים, אך לא משתפרים בכל
אותם מקרים שהוא ממילא עובד מול ה- cache שלו, ואלו מקרים רבים. לכן שמים את הדגש על מהירות שעון גבוה, IPC
גבוה, ו- cache גדול ומהיר, שתרומתם לביצוע CPU היא גדולה יותר בחשיבותה מבחינה סטטיסטית. אם מנגד
(לדוגמא) מדובר בשרת SQL, שיש לו נפח RAM גדול, ומסוגל לאכסן (למשל) את ה- DB כל כולו ב- RAM, או אז
למהירות הזכרון תהיה השפעה גדולה על ביצועי השרת, היות וכמעט כל פעולה מול ה- DB היא מטבע הדברים נעשית
מול ה- RAM, לא מול הדיסק, (ולא מול ה cache שאינו מסוגל לאכסן אפילו גרגר מגודלו של ה DB כולו).
האם הצלחתי להשיב בצורה טובה ?

-
1
-
-
ציטוט של captaincaveman
אז איך מסבירים את זה שלמרות של-3090 20% יותר CUDA cores (וגם רוחב פס גדול יותר למיטב זכרוני, וכמובן יותר זיכרון), הוא לא נותן שיפור שמתקרב לזה בביצועים לעומת ה-3080?
מכיוון שישנם עוד משתנים במערכת שמעכבים את הביצוע הכולל ופוגמים בנצילות.
במקרה של היחס בין רסטריזציה ל- RT (שהוא פנימי לכרטיס), הגורמים החיצוניים שמשפיעים, משפיעים באופן זהה
והומוגני על הכל שבתוך הכרטיס, ולכן השלכתם לינארית. פגיעה ב- X על רכיב רסטריזציה, מייצרת גם פגיעה זהה על
רכיב RT.
עקרי הדברים החיצוניים שעשוים לפגוע בנצילות הכרטיס הם המחשב עצמו, הפלטפורמה, שהמעבד הגראפי ממתין להם
שיתנו לו את ה- OK להתקדם. IO מול רכיביו השונים של המחשב, וחישובי המעבד.
אך ההאטה הזו פוגמת כאמור (וגם הגיוני), על כל פעולות הכרטיס 3090 באופן המוגני וליאנרי, על כל מרכיביו גם יחד.כשהכרטיס ב stall הוא ב- stall על הכל.
אחת התופעות שנוכל לראות היא, שכרטיס חצי הספק לא מספק בדיוק חצי ביצועים, אלא קצת יותר טוב מחצי. נגיד 55%.
ואחרי זה כרטיס רבע שוב, יותר טוב מרבע נגיד 30%.
ההסבר:
ככל שהכרטיס הגראפי איטי יותר, כך האלמנטים החיצונים (שהם המחשב עצמו), פחות מזיזים לו. כי ישנם פחות מצבים
שהוא זה שממתין למחשב, מאשר שקורה במאיצים חזקים, שהם בדר"כ נאלצים (בשל עוצמתם ומהירותם הרבה) להמתין
למחשב יותר זמן באופן יחסי.
נצילות כרטיס מסך עולה, ככל שעוצמתו נמוכה יותר, בשל הקטנת ההזדמנויות - שהמחשב הוא זה שמעקב אותו.
-
שאפו,
יפה ונעים לראות חברים שמגיעים מעולמי ומסוגלים להעריך. אינך רק מפגין ידע ברמה גבוהה של מדעי המחשב ראיתי
בשרשורים אחרים (גם), אלא שואל (פה) את השאלות הנבונות והנכונות ביותר. אהבתי
לשאלותיך אחת אחת: (טקסט שלך בשחור מענה שלי בכחול)
דבר ראשון, רציתי לשאול: האם יהיה יתרון ב512MB? הרי לcache של המעבד אנחנו צריכים הרבה בלוקים קטנים כי התוכנית קוראת מהRAM לא בהכרח ברצף, אבל כיוון שהGPU מעבד frame frame זה ברצף בזיכרון, כך שלכאורה נרוויח מהכפלת הcache רק במידה שתוכפל מידת המקבילות של הGPU, לדוגמ' שבמקום לעבד טקסטורה אחת כל פעם הוא יעבד שתיים (המספרים להמחשה בלבד), או שנכפיל את הרזולוציה.
פגעת בול - להבדיל מ CPU שבו אפיון הקריאות הוא מסוג random access to the memory, בעבוד גראפי זה
הרבה יותר מסודר. המעבד הגראפי קורא מקטעים די ספציפיים בכל אטרציה של פעולה. ולכן פחות חשובה יכולת
random access memory עבור GPU, והרבה יותר חשוב לו זה memory access to specific memory
addresses ברובד של קריאות. כתיבות זה לא מעניין, הוא כותב למרחב מצומצם של frame buffer.
ומשכך, כל עוד בכל איטרצה של סוג של פעולה חישובית, מרחב הכתובות שהוא זקוק להם יכול להתחם על ידי buffer
בגודל ברור וקבוע, הגדלת אותו buffer לא ממש תשפיע על הביצוע. ולכן, אם נמצא ש- 128MB מספקים את הצורך
עבור 4K, ועבור גודל הטקסטורות שבהם עורכים שמוש בתעשיית ההאצה הגראפית דהיום, אזי הגדלת נפח ה- buffer
מעבר לכך בקושי תשפיע אם בכלל. אבל מה כן, אם ישתמשו ברזולוציות גבוהות יותר לדוגמא 8K, היא לבדה צורכת רק
עבור frame buffer פי 4 נפח מ- 4K, שמשמעו 128MB לפריים בודד! ואז 128MB cache אינו מספק עוד וזה מצב
שיחייב מעבר ל- 256 או 512MB לפחות. עוד אפשרות היא עליה באיכות הויזואלית של טקסטורות, לגדולות יותר,
שתופסות יותר נפח זכרון בתורן, מה ששוב עשוי לאלץ להגדיל את ה- cache למעל 128MB. אז נסכם כך:
כל עוד לא עולים ברזלוציות למעל 4K , וכל עוד גודלן של הטקסטורות אינו עולה משמעותית מהנפחים המקובלים
בתעשיה כיום, כנראה שלא יהיה ערך מוסף ממשי ב- cache גדול יותר מעל 128MB הנוכחי.
דבר שני, למעשה זה קצת עצוב עבורנו כצרכנים. כי זה בעצם אומר שאין כמעט שיפור בRDNA2 לבד מזה, מה שאומר שבדור הבא (?) כשNVIDIA תאמץ את הטכנולוגיה גם היא שוב נגיע לGEFORCE 40 חזק פי שתיים מNAVI 3. מכיוון שאם אני מבין נכון, GeForce 30 חזק יותר מBIG Navi, רק שהיתרון של הcache מציב אותם באותה רמה.
כן ולא וזו יותר הערכה שלנו. הדבר הראשון הוא נכון, מכיוון שאי אפשר להגן על הטמעת ה- cache כיישום בעבוד גראפי
וכל אחד יכול להטמיע כרצונו, ומשהשיטה הזו והיתרון שלה ברורים מאליו בעוצמתם, למעשה יחייבו את כולם להטמיע
במוקדם או במאוחר anyway, סביר מאד אם לא די וודאי , שנוידיאה מיישמת אותו כבר בסבב הבא סדרת 4000. ואז גם
היא תהנה מאותו יתרון עצום כמו ש- navi21 נהנה. משמע שגם נוידיאה תוריד מסדר היום את בעיית מגבלת הרוחב
פס זכרון ותמגר את הלחץ הזה סופית.
כמו כן אין ספק שהפטנט החדש מאפשר לליבה של navi21 לעבוד בנצילות גבוה יותר מ- ga102 ורוב הזמן אולי נצילות
100% ממש שהיא למעשה נדירה. ולכן יכולה לחלץ יותר ביצועים מפחות בוכנות במנוע.
במקרה ששתי המתחרות אינן סובלות ממגבלת רוחב פס זכרון כמו שיהיה בדור הבא, עולים על פני השטח וכדבריך, אך
ורק הפערים הביצועיים של הליבות. טענת שסדרה 3000 חזקה יותר מ- big Navi. אני לא בטוח שזו קביעה שניתן
לעשותה היום בוודאות, אם כי קו המחשבה שלך מובן לי, לאור מה שצריך לפצות בצד נוידאה על הנצילות המופחתת
ברובד זכרון. חסר לנו מידע מספק להבין איזו מהליבות ga102 או navi21 חזקות יותר. יחסי המרכיבים שכל אחת הטמיע
שונים, לכל אחת מהליבות לבטח יתרונות במקומות אחרים על פני האחרת.
למשל אני כבר ער לכך שהשבבים של navi21 כנראה חזקים יותר ברזולוציות נמוכות, והשבבים של ga102 חזקים יותר
ככל שהרזולוציה עולה. הדבר עשוי לנבא לנו כי מרכיב הגאומטריה אצל navi21 עדיף לעומת מרכיב הרסטריזציה, בעוד
שאצל נוידיאה זה הפוך וזה כבר משהו שאנו יודעים שהם שינו בסדרה 3000 לעומת הסדרות הקודמות.
בקיצור, כששתי החברות תאמצנה את ה cache ולא רק AMD, נהיה חכמים יותר. עוד שנתיים ?
נמתין בסבלנות.
מה שבטוח הוא, למי שמבין את המטריה, מי שקרה מה שהסברנו במאמר והבינו כהלכה, וזה לא טריויאלי למי שאינו
מגיע מרקע מתאים, לכן ניסיתי הכי טוב שאני מסוגל להסביר לאדם הפשוט ומקווה שהצלחתי, זה ש- AMD הביאה פה
שיחוק אלגוריתמי מארץ האסים בשרוול, וזה מדהים שהם חשבו על ליישם זאת ראשונים בתעשיה. זה game
changer. יש חכמי מתמטיקה ולאגוריתמיקה ב- AMD היום, ללא ספק. ברמה הגבוה ביותר. ולכן המגרש פתוח היום
לתחרות, וזה בואו נקווה, מה שיהיה מעתה ואליך לשנים הבאות. אילו רק יכלו להגן על הפטנט ל- 7 שנים זה היה
מאפשר בידם לפתוח פער יפה על נוידיאה, שהיתה נחנקת בלי רוחב זכרון מספק, או שהיה יוצא לה מאד יקר ליישם זכרון
מהיר אבל בשיטת brute force.
תבינו חברים, הטמעת cache במעבד גראפי היא אחת הרבולוציות הדרמטיות ביותר שנולדו אי פעם בעולם ההאצה
הגראפית. יתכן שהוא יכול להחשב, כגדול ההמצאות אי פעם בתחום, או לפחות אחד מהשלושה הגדולים ביותר.
לא מפליא איך הם במכה אחת סגרו פער של עשור מול נוידיאה ולו רק בגלל הפטנט הזה, שכמה שהוא פשוט, ככה הוא
גאוני. אני מת לפגוש את המדען/מהנדס שהגה אותו. מת לשוחח עימו. הוא ראוי לדעתי לפרס מדעי כלשהו. תרומתו
לאבולוציית המדע בתחום מרשימה.
-
1
-
-
ציטוט של amit14
לא לגמרי הבנתי..נניח ש2080ti מריץ משחק על 100 fps..וה3080 חזק ממנו ב50% ומריץ על 150..
מפעילים rt והביצועים יורדים ב50%..עכשיו ה2080ti עם 50 fps..וה3080 עם 75..עדיין יותר חזק ממנו ב50%..אבל זה הפער שהיה גם ברסטליזציה רגילה...מצופה שאם יש שיפור בrt הוא יפתח במקרה הזה פער גדול יותר,שהביצועים ירדו בפחות אחוזים..זה לא שהrt פועל בחלל ריק...זה עוד לבל שנוסף..
אכן כפי שכתבת.
אנסה להסביר ברור יותר:
נוידיאה מטמיעה בשבב הגראפי שלה יחידות עיבוד לטובת רנדור מסורתי, רסטריזציה, ויחידות עבוד לטובת חישובי RT.
היא חישבה ומצאה בשעתו ייחס כלשהו כאופיטמאלי לדעתה, ואת היחס הזה הטמיע בדור RT הראשון הידוע בשמו סדרה 2000.
כשהיא יצרה את דור 3000, מסתבר לנו, שהיא שמרה על אותו יחס אופטימאלי שמצאה בדור הקודם ולא שינתה אותו.
למרות שב- PR לקראת השקת סדרה 3000 ובכל ההדלפות שיצרו קודם להשקה (ספק אולי מטעמה בכוונה), היא שווקה
כי יכולות RT קפצו מדרגה לעומת הדור הקודם. הדבר גרם לנו לחשוב שהפעם המחיר הביצועי בהפעלת פונקציה זו יקטן.
בפועל יכולות RT התחזקו ביחס לינארי לשפור שחל מדור 2000 ל- 3000 והיחס רסטריזציה לחישובי RT נשמר.
משמע, שעם כרטיס 2080ti כדברך סופג מחיר של 50% כשמפועלים עליו יכולת RT, נובע שגם ב- 3080 המחיר יהיה זהה.
אם מקודם היחס היה 150 לעומת 100, והמחיר הוא 50% בעת הפעלת RT, אזי היחס החדש יהיה 75 ל- 50 ובדיוק כפי שכתבת.
כמעט בכל הרבדים, עבוד גראפי הוא לינארי מתמטית.
-
ציטוט של af db creid
כמעט מדויק. משום שאם התוכנה כבר תוכנתה בצורה כזו שהיא מחלקת את העבודה לthreads נפרדים, הcontext switch מאט את העבודה. עם זאת, יש לקחת בחשבון שחלק מהתוכנות יspawnנו (איך למען השם אני אמור לתרגם את זה? "להשריץ" threads נשמע גרוע...) threads רק אם יש מספיק ליבות.
זה נכון בתאוריה, אלא שבפרקטיקה, היות והמעבד של n תהליכים לא יועמס ב Load מושלם של 100%,
תהיה שם תקורת ביצועים שהולכת לפח. ולכן ה- context switch שיגרם במעבד בעל הליבה הבודדת,
תקורתו בטלה בשישים לעומת המקרה האחר.
עכשיו,
באם לא מדובר ביישום real time, ניתן לקנפג את השעון החלפת תהליכים של מערכת ההפעלה, לבצע החלפה רק פעם בעשירית השניה
נגיד. ואז מדובר בכולה 10 החלפות בשניה - תקורה של פחות מפרומיל שהולכת לאבוד. לכן כל נושא ה- context switch הוא תאורטי יותר
מאשר משפיע בפרקטיקה באמת, בתדרי מערכות ומעבדים של המחשבים כיום. פעם כשמעבד עבד בתדר נמוך והזכרון וה IO היו איטיים
נתנו ל context switch משקל יותר ממשי. כיום נעשה לאפסי/זניח.
הגדולה האחרת היא שמעבד בעל ליבה בודדת, מאפשר ניצולת מלאה של הביצוע על למקסימום של 100% של כל הספקו.
גם לנסות לעשות זאת בתהליך פרללי שאפשר למקבלו לחלוטין, זה אף פעם לא יוצא מושלם, גם במקרים מאד טהורים.
איזה 1% in the best scenario הולכים לפח. context switch שמתרחש פעם בעשירית שניה על מעבד 4Ghz
זה אבדן ביצועי השואף לאפס - הרבה פחות מ 1%.
מעל הכל, חלק לא מבוטל מהאלגוריתמים אינו מאפשר למקבלם מלכתחילה, ואז בכלל.
נגיד יש מעבד 8 ליבות, ההספק של ליבה הוא שמינית כח. ומעבד בהספק פי שמונה ביחס לליבה בודדה שלו, הוא דרמתי בעוצמתו, פי 8.
החלום הכי רטוב של עולם המחשוב הוא ליבה אחת עוצמתית. על העקרון הזה מבוססים חלק ממחשבי העל לחישובים
בלתי ממוקבלים. מכונות מסוג זה מטמיעות חומרים איזוטריים ויחודיים המקוררים ככל שניתן קרוב לאפס המוחלט כדי
להופכם למוליכי על. רק כך ניתן להגיע לתדרי עבודה דרמטיים, שמאפשרים מקסימום הספק למעבד/ליבה בדידה. הכל
לטובת אותם חישובים שלא ניתן למקבלם.
-
1
-
-
ממש לא נעלב שתנוח דעתך

עברית אינה החוזקה/השכלה/קריירה שלי, אז בכלל אדיש...
למדתי עברית ממקור אחד, יש עוד רבים. הנושא אינו חד חד ערכי כמו תחומי המדע. והאמת, זה לא כזה מעניין. ביננו...
יתכן שתיקנתי את החבר jaber ויתכן שתקנתי לא נכון. אבל יפה שנכנסת למצוא חומר בנושא
כולנו למדנו בזכות.
-
1
-
-
פריצת דרך בעולם ההאצה הגראפית - cache

https://hwzone.co.il/community/topic/600884-פריצת-דרך-בעולם-ההאצה-הגראפית-cache/
-
- תגובה פופולרית
- תגובה פופולרית
נכתב על ידי חבר הפורום nec_000, בתאריך 29.10.2020
**ישנו אישור הכותב לבעלי האתר, להשתמש במאמר שלהלן ככל שיראו לנכון, ובתנאי שיזכירו את הכותב בעת הפרסום/השמוש.
לפנינו מאמר אודות הטכנולוגיה החדשה פורצת הדרך, אשר הוטמעה לראשונה בדור החדש של כרטיסי המסך.
במאמר נבין מה היא, מדוע היא נכנסה לתמונה, מה הגדולה והגאונות שבה, איזו בעיה שורשית היא באה לפתור בתעשיה
הגראפית, ומדוע היה ניתן להטמיעה לראשונה רק עתה (מבחינה טכנולוגית), ומדוע למעשה מעתה ואילך יאמצו אותה כולם.
רקע:
כולנו שמענו אתמול בעת השקתה של סדרת RX6000 החדשה של נוידיאה, אודות טכנולוגיה חדשה ושמה infinity cache.
הבנו שזה משהו ש- AMD הטמיעה במוצר החדש, אבל לא הבנו איך זה בדיוק עובד, מדוע, ומה זה עושה. אז היום כולנו
נבין ונבין היטב. קודם כל למען הפשטות המילה infinity היא מיתוגית, אין לה משמעות. ואנו נקרא למנגון בצורה הכי פשוטה
ונכונה טרמינולוגית, cache.
המאמר מובא לטובת החברים, השכלת ידיעתם והרחבת הנושא, לתת הסבר ברמה אקדמאית (אך מתומצתת) כזו שיכולה להכנס
בדף אחד מרוכז, ולהעביר את התורה. ברמה שעושה סדר ומאפשרת בידי החובב המצוי, להבין את הנושא ברמה טובה.
רקע הסטורי:
לפני עשרות שנים נולד לראשונה כרטיס המסך הראשון שאפשר בידי המחשב להציג על גבי מסך את הפלט המבוקש.
בהתחלה היה מדובר רק בטקסט, וזה הספיק כדי שהוא יוכל לדבר ישירות מול ה- RAM האיטי ולא היה נדרש לכלום מעבר.
אך לימים נכנס צורך להציג לא רק טקסט פשוט, כי אם יכולת גראפית מורכבת יותר, שהולידה קושי:
אחד המשאבים הכבדים ביותר שנצרכים בעבוד גראפי הינו תעבורת זכרון גבוהה וגדולה. אנו נסביר בהמשך מדוע.
לכן כרטיסי המסך נאלצו עם השנים להפסיק ולהשתמש בזכרון RAM הגנרי של המחשב (שהיה איטי מדי עבור משימה הזו),
ולהתחיל ולעבוד בעזרת זכרון מהיר שהורכב על גבי כרטיס המסך עצמו. זה שימש כ- buffer זכרון יעודי (ומהיר) לשמוש המעבד
הגראפי גרידא, באופן dedicated. הוא היה מהיר יותר בסדר גודל מה RAM של המחשב. קראו לו זכרון גראפי. לימים
שמו נקבע כ- Vram.
בכך אפשרו בידי המעבד הגראפי (שכיום קוראים לו GPU) מהירויות גישה גבוהות ורוחבי פס משודרגים ביחס לאלו
שיכול היה לספק לו RAM רגיל של המחשב. הרוחב פס המשודרג אפשר בידי ה- GPU לבצע עבודת עיבוד תמונה אפקטיבית.
בלעדיה ה- GPU היה למעשה במצב starvation - חנוק ורעב ל- DATA.
במהלך השנים חוק מור הראה שמדי 24 חודשים (כשנתיים) ישנה הכפלה בקצב הכח/עיבוד של המעבדים הגראפיים.
הסיבה להכפלה מבוססת על קפיצת מדרגה ברובד הליטוגפריה אחת לשנתיים בממוצע גס, שאפשרה להכניס
פי 2 טרנזיסטורים באותו גודל שבב, (וכמובן תוספת קלה לתדר העבודה). בזכות שניהם ביחד, זו הביאה ליידי הכפלת
ביצועים של פי 2 (לפחות) מדי אטרציה (שנתיים).
הבעיה היא, שבעוד ששבבי העיבוד הגראפי מעלים את הספקם כמתואר לעיל בקצב מהיר ואקספוננציאלי, לא כך מתאפשר
לבצע בנושא רוחב פס הזכרון העומד לרשותו של המעבד הגראפי. משום שבזכות הקטנת הליטוגרפיה פי 2 בכל אטרציה,
לצערנו לא מתקבלת מכך הכפלה מקבילה ברוחב פס הזכרון, אלא רק הכפלת נפח הזכרון, שהיא אינה המשאב הבעייתי
בספור שלפנינו.
בואו נראה למה מוביל מצב שכזה ברבות השנים:
בעוד שמדי אטרציה, אחת לשנתיים כאמור, הכח החישובי שמתאפשר לקבל מהמעבד הגראפי מוכפל, לא ניתן היה לספק
עבורו קצב עליה זהה ומקביל גם של הכפלת רוחב פס הזכרון. וכך נוצר עם הזמן פער, שמצד אחד הכח העיבודי הולך
וגדל בקצב מהיר של פי 2, בעוד שרוחב הפס גדל בעצלתיים. נוצר מה שנקרא התרחקות משאב אחד מהשני שלא יכל
להדביק את הקצב שלו.
אז במשך השנים נתנו לבעיה הזו מענה בדמות הטכניקות הבאות:
הכפלות הולכות ונשנות של רוחב הפס גישה לזכרון בסיביות: עלו מ- 64 סיביות ל- 128, לאחר מכן ל- 256,
וכך עד 512... ובסוף הגיעו לתקרת זכוכית כזו, שהיא מגבלת היכולת לדחוף trace-ים נוספים על גבי לוח
PCB של כרטיס מסך בודד. עצרו (פחות או יותר) במגבלה של 512 נתיבים (traces) בלוח PCB. מעבר לכך מורכב
ויקר מדי.
כמו כן נקטו בעוד שיטה, והיא העברת יותר מידע בכל פעימת שעון. בהתחלה זכרון עבד ב- SDR, שזה כתיבה או קריאה
של סיבית בודדת פר קלוק. לאחר מכן עברו ל- DDR, שזה כתיבה אחת וקריאה אחת של סיבית פר קלוק.
לימים עברו בדור GDDR5 לשתי כתיבות ושתי קריאות של סיבית פר קלוק ובסה"כ 4 סיביות לפעימה.
כיום אנחנו כבר בדור GDDR6X שהגדיל את האמור לשמוש ב- 4 bit פר פעימה, שמשמעותם 16 ערכים שונים פר
קלוק. האמור מייצג סיגנל מאד קשה לשליטה ולאמינות. שכן סיגנל 4 סיביות משמעותו 16 ערכי מתח שונים בכל פעימה,
ולכן קרובים מאד זה לזה, כך שהזיהוי מה היה הערך הנכון הולך ונעשה קשה לבקר. המשימה מצריכה אבחנה מאד עדינה
בצד הבקר אשר מובילה לשגיאות לא מעטות. יש גבול בעבוד אותות חשמליים ואנו מתקרבים לגבול הזה בצעדי ענק.
ולנסות להמשיך ולעלות מכאן הלאה מתחיל להיות אתגר קשה במיוחד, על גבול הלא מעשי או הלא כדאי טכנית.
שיטה נוספת שדי מוצתה עד הטיפה האחרונה בעשור האחרון היא דחיסת מידע, בתחילה בצעו ברמת lossless
ולאחרונה הגדילו לבצע אף ברמת lossy compression, הכל במטרה לנסות ולחלוב כל טיפת מיץ אחרונה שניתן
על מנת לתת בוקטור של רוחב פס הזכרון, מענה כלשהו אפקטיבי לקצב המסחרר שבו המעבדים הגראפיים מתקדמים
ונוסקים מעלה, בעת שהזכרון לא מצליח להדביק אותו בקצב מספק.
כל השיטות לעיל, הרחבת רוחב הפס בסיביות (עד 512), שמוש בסיגנלים מורכבים להעברת יותר מידע פר קלוק
לזכרונות (4 סיביות), דחיסת מידע, הגיעו בעת המודרנית לקצה גבול היכולת, עד כדי שלא ניתן להתקדם עוד רבות
בנושא, וחייבים, ממש חייבים למצוא שיטה חדשה ופורצת דרך בכדי להתגבר על מגבלת רוחב פס הזכרון והמעבד
הגראפי הרעב. הבינו, בלי רוחב פס שימשיך ויעלה על מנת לתמוך בהספק העיבודי שהולך ועולה, לא נוכל להתקדם
בעבוד הגראפי ונגיע לסטגנציה.
השיטה החדשה שנמצאה:
שמוש בזכרון מטמון.
הבעיה הגדולה בעבוד גראפי היא כאמור כמויות הזכרון האדירות שהעבוד הזה מצריך. הסיבה שנדרשת כמות זכרון
רבה נובעת מכך, שגודל הקלט הוא ענק. מרחב טקסטורות גדול וכבד והוא זה ששותה את רוב רובו של נפח הזכרון
הלכה למעשה. הוא זה שמציבים אותו ב- buffer של הכרטיס, להלן ידוע בשמו Vram. כי אם היו שומרים אותו בזכרון
הכללי של המחשב (ב- RAM) כבר הבנו מההסבר מעלה, למעבד הגראפי היתה נגישות מאד איטית אליו, ולכן רוב הזמן
המעבד הגראפי היה מבלה בהמתנה על סרק למידע שיגיע אליו. או בקיצור, היינו נתקלים בנצילות מאד נמוכה במעבד
הגראפי ובביצועים עלובים. לכן במקור הומצא ה- VRAM, על מנת להביא קרוב למעבד הגראפי את כל המידע הנחוץ
לו לשם עבודתו, כדי שיוכל לעבוד מהר ולא יסבול מהרעבה ל- DATA. זה הרי היה טפשי אילו יש מעבד חזק, שכל הזמן
ממתין למידע ולכן עבודתו מעוכבת.
היות והזכרון הנצרך כאמור הוא גדול נפח, וטקסטורות צורכות את רובו הגדול והמכריע, לא היתה שום דרך לייצר למעבד
גראפי נפח זכרון מטמון ממש עליו, בנפח כזה, שיכל להחזיק את כל אותו מידע שנחוץ. מה שהיה טוב ומתאים לעולם
המעבדים CPU, זכרון מטמון קטנצ'יק, אינו מתאים ליישומים גראפיים. למעבד CPU מספיקים נפחי מטמון קטנים מאד,
זה אופן העבודה שלו, ששונה מעבוד גראפי, שמצריך מטמון ענקי כדי להיות רלוונטי. ולכן כל משך עשרות השנים היכולת
להטמיע זכרון מטמון, לא היתה אפשרית או מעשית במעבדים גראפיים.
רק עתה משהליטוגרפיה לראשונה הגיע לרמה של 7nm, מתאפשרת צפיפות טרנזיסטורים מספקת שמקנה את האפשרות
להחזיק כמות גדולה דייה של טרנזיסטורים בשבב אחד. הדבר אפשר בידי יצרני המאיצים הגראפים את האפשרות הטכנית
כן להטמיע זכרון מטמון מספק מבחינה פרקטית במעבד הגראפי.
המעבד הגראפי הראשון בעולם, להלן החלוץ הטכנולוגי שמטמיע זכרון מטמון (בנוסף ל- Vram), כשכבת ביניים,
הוא ליבת Big Navi הידועה בשם הקוד Navi21. ליבה זו היא מגודל כ- 500 (פלוס) מ"מ רבועים, שכוללת כמות אדירה
של 26 מיליארד טרנזיסטורים, מתוכם מוקצים כ- 6 מיליארד (רבע מכל הנדל"ן של השבב) לטובת זכרון מטמון בגודל 128MB.
128 מגה בייט, הם 128 מיליון bytes. ב- byte יש כידוע 8 סיביות, ולכן 128Mbytes הם בעצם 1,024 מגה ביטים,
או 1.024 מיליארד ביטים. נדרשים באלקטרוניקה שבבית מהסוג הנדון, על מנת לאכסן מידע של סיבית אחת, כ- 6 טרנזיסטורים.
ולכן 1.024 מיליארד ביטים, צורכים 6 מיליארד טרנזיסטורים על מנת לייצגם. להלן מובנת אותה הקצאה בגודל 6 מיליארד טרנזיסטורים,
הנדרשים להלקח מהנדל"ן של השבב, לטובת מערך זכרון מטמון בגודל 128Mbytes.
מדוע רק עתה לראשונה התאפשר להטמיע את זכרון המטמון במעבד גראפי ?
משם שאם נלך רק דור ליטוגראפי אחד אחורנית, לדור של 14/16nm, נוכל לראות שכרטיסי המסך המבוססים עליו היו מגודל
של כ- 11 מיליארד טרנזיטורים לכל היותר (השבבים הגדולים שבהם). ברור שאם נדרשת הקצאה של 6 מיליארד טרנזסיטורים
(מתוך 11), נוצר מצב שיותר ממחצית השבב הולכת לפח רק עבור הזכרון מטמון, כך שלא היתה נשארת כמות מספקת של טרנזיסטורים
לטובת מרכיב העיבוד הגראפי של השבב. אך כיום כאשר הליטוגרפיה לראשונה מאפשרת הטמעתם של לא פחות מ- 26 מיליארד
טרנזיסטורים בשבב בודד, הקצאת רבע מהם לטובת הנושא (6 מתוך 26) הופכת לאפשרות מעשית ליישום. כי נשארו בשבב עדיין
20 מיליארד טרנזיסטורים לטובת העבוד הגראפי וזו כמות מספקת. יחס של 25% לטובת מטמון ו- 75% לטובת עבוד זהו יחס שלראשונה
נעשה למעשי. וזה משהו שלא היה ניתן לבצעו בעבר, בגלל שלא היתה אפשרות לכזו צפיפות גדולה של טרנזיסטורים בשבב בודד,
ואילו היו כן מעיזים להטמיע cache גדול דיו, לא היו נותרים מספיק טרנזיסטורים זמינים ליתר צרכי השבב.
עולה השאלה החכמה הבאה:
מה מיוחד כל כך בזכרון מטמון בגודל 128MB, שהוא מספר הקסם, שלא היה אפשר לבצעו בגדלים קטנים יותר מ- 128MB למשל ?
קצת הבנה איך פעולת עבוד גראפי מתרחשת (במתומצת):
ישנם כמה שלבים של עבוד עד לבניית התמונה, ואנו נדבר מאד בפשטות כדי להקל על עובי היריעה.
המעבד הגראפי מקבל מהמעבד הראשי סט הוראות לביצוע ובניית תמונה. בכללן קודקודים שמרכיבים את הפוליגונים,
ואת הטקסטורות, שכאמור נשמרות אצלו מקומית ב- Vram. כל מה שהכרטיס מסך מקבל מהמעבד הוא שומר קרוב אליו ב- Vram
כדי שיוכל להרכיב מהם את התמונה במהירות וללא עכובים או המתנות, ה- VRAM הוא משטח העבוד המהיר והפרטי של המעבד הגראפי.
בשלב הראשון המעבד בונה מהקודקודים את הפוליגונים (מצולעים תלת מימדיים), שנקרא השלב הגאומטרי.
בשלב הבא הוא מרנדר את הפאות של הפוליגונים, קרי מצייר וצובע אותם. הוא מצייר/צובע אותם מהטקסטורות שמרכיבות
את אותו אובייקט (טקסטורה היא פיסת תמונה). כלומר הוא לוקח טקסטורה ופורש אותה על פני פיאת המצולה. המושג המתמטי כאן
הוא טרנספורמציה לינארית ממרחב דו מימדי של התמונה (הטקסטורה) למרחב תלת מימדי שהוא הפאה (הפוליגון).
יש עוד כמה שלבים כמובן, שלבי ביניים, ושלב אחרי הרסטריזציה (רנדור הפאות מהטקסטרות) בכללן חישובי תאורה וכדומה...
לא נכנס במאמר הנוכחי מעבר, למרות שהנושא מאד מעניין, אך בעיקר משום שכרגע זה אינו הסקופ הרלוונטי לכותרת הדיון.
מה שאותנו מעניין להבין והכי חשוב זה, שהשלב של הרנדור (שזה לקחת את הטקסטורות וציורם/פריסתם על גבי הפאות) זהו השלב
הכי כבד במונחי צריכת זכרון, קרי IO מול VRAM. ככל שצרכו יותר רזולוציה, או צרכו יותר פריימים לשניה, צריכת העיבוד מוכפלת
באופן לינארי ועימה מוכפלת הצריכה של רוחב פס הזכרון. שכן כל פעולת עבוד של פיקסל מצריכה קריאתו מהמפה של הטקסטורה,
וכתיבתו על פאת הפוליגון המתאימה.
קריאה, עבוד, כתיבה... וחוזר חלילה פיקסל אחר פיקסל. ופי X יותר פיקסלים, מצריך פי X יכולת עיבוד (שזה קל להשיג הבנו כבר)
אך גם פי X רוחב פס זכרון. הם הולכים יד ביד וצמודים האחד לשני. המעבד לא יכול לעבד עוד פיקסל, באם הזכרון לא מאפשר לו
לקרוא אותו. והוא לא יכול לכתוב עוד פיקסל על הפוליגון, באם הזכרון לא מאפשר לו לכתוב אותו. הבעיה שלנו והמגבלה היא, שלא ניתן
לשפר את רוחבי פס הזכרון באותו קצב שניתן לשפר את המעבד הגראפי. להלן בעיית הרעב לרוחב פס זכרון.
אחת הדרכים החדישות לפרוץ את תקרת הזכוכית ברובד הבעייתי שהוא כאמור רוחב פס זכרון, היא לצור משהו מהיר יותר
מה VRAM, להלן זכרון מטמון. זהו זכרון שקרוב עוד יותר למעבד הגראפי ומורכב עליו ממש, שהוא בעקרון, לא מוגבל עוד, וגדל
בעוצמתו במישרין עם גדילת השבב עצמו. יותר טרנזיטורים מובילים ליותר גודל שאפשר להקצות כמטמון, אבל גם ליותר רוחב פס,
משום שרוחב הפס בזכרון מטמון הוא לינארי לתדר הפעולה של השבב, ולכמות ה- interconnects שבנו על השבב עצמו, בין
הזכרון מטמון לבין הבקר זכרון שיושב בשבב עצמו גם הוא.
מדוע אם כן 128MB זכרון מטמון זהו הרף, שלראשונה נותן גודל מספק, ולא היה אפשרי להתספק בהרבה פחות מכך ?
משום שמרגע שניתן לבצע שתי פעולות יסוד עקרוניות, והן החזקת לפחות טקסטורה אחת שלמה כל כולה בתוך הזכרון מטמון,
ומרגע שניתן להחזיק frame בודד בשלמותו בתוך הזכרון מטמון בו זמנית, לראשונה ניתן למעשה לבצע את כל החישובים
הנחוצים לרנדורה של תמונה אחת שלמה, רק באמצעות הזכרון מטמון, וזה מה שהיו צריכים כסף מינימאלי להגיע אליו.
frame בודד מגודל HD שזה 1080P, ללא דחיסה, הוא 2 מליון פקסלים לערך, ביצוג 32 סיביות לפיקסל, מניב 64 מיליון ביטים,
שהם 8 מיליון bytes, שמשמעותם 8MB זכרון נצרך להחזקתו.
ובתמונה בגודל 4K הסכום מוכפל כידוע פי 4, קרי 32MB נצרכים להחזקת פריים בודד.
די מהר מבינים פה משהו כזה, שכדי לבצע את כל עבודת החישובים הנדרשת לטובת פריים מלא, נפח זכרון מסדר גודל
של 128MB, הוא הסף המבוקש להבטיח, שהכל נכנס בתוכו בו זמנית. הכרטיס הגראפי לוקח במצב שכזה טקסטורה אחת
בודדה, מכניס את כל כולה לזכרון מטמון, קרי קורא אותה רק פעם אחת בלבד מה VRAM, שנגיד היא צורכת כמה מגביטים,
והוא מתחיל לצייר פיקסל אחר פיקסל ממנה ולכתוב אותם ל- frame buffer, כאשר כל כולם יחדיו מצליחים להתכנס בו זמנית
לנפח זכרון מטמון בגודל 128MB שהוקצע למעבד הגראפי.
128MB זהו איפה הנפח המינמאלי הפרקטי הראשון, שמאפשר את העסק הזה לעבוד (גם) ב- 4K.
נפחים קטנים יותר מכך מקשים, עד כדי לא מאפשרים לבצע את הכל בבת אחת, ומכלים את כל החוכמה וראציונאל שבשמוש
בזכרון מטמון.
אמרנו שלא נכנס לעומק בכל תהליך העבוד הגראפי, ישנם כמובן עוד שלבים וזה לא רק ציור טקסטורות, אך נסתפק בכך שנסביר,
שכל החישובי ביניים של כל יתר השלבים, וחישובי התאורה בסוף ושות'... עורכים את החישובים שלהם ללא צריכת נפח זכרון גדולה,
והם יכולים לבצע purge לאחר סיומם ולהזרק החוצה מהזכרון מטמון ולפנותו, כי אין צורך בהם עוד.
מה שחשוב להבין זה, שהצרכן הכבד ביותר זהו שלב הרסטריזציה, או שלב הרנדור, שמשמעו ציור הטקסטורות על פני הפאות של
הפוליגונים. ואם נכנסת טקסטורה שלמה אחת ב- cache וגם פריים שלם ב cache בו זמנית, זה הגודל הכי קריטי בכל התהליך.
וזה מה שמתאפשר באמצעות זכרון מטמון בגודל 128MB , ולא כל כך מתאפשר בגדלים קטנים מכך. לכן היו צריכים להמתין
עד שנת 2020 וש- 7nm תיוולדנה, כדי שיהיה אפשרי מעשית/פרקטית לבנות cache בגודל מינימאלי מספק.
מעטה הכרטיס הגראפי טוען טקסטורה אחת ל- cache, מסיים לרנדר את מאות ואלפי הפוליגונים שהיא משמשת לציורם באותה
תמונה, ואז הוא זורק אותה מהזכרון מטמון, טוען את הטקסטורה הבאה בתור וחוזר חלילה עד שסיים עם כולן.
נוכל לשים לב שבשיטה הזו, כל טקסטורה נקראת רק פעם אחת פר תמונה שלמה, לא משנה כמה פוליגונים יש בה.
המעבד לא יסיים עם הטקסטורה שב- cache עד אשר יסיים לצייר את כל הפוליגינום שטקסטורה זו משמשת לציורם,
שזה מאות ואלפי פעמים בתמונה בודדת.
נוכל מיד להבין, שנפח רוחב פס הזכרון בכוון read מול ה- VRAM שנחסך פה הוא באלפי מונים. שפור דרמטי.
ובצד הכתיבה, נזכורה שה- frame buffer אינו יושב ב- VRAM עוד (שמשמעו שלכל כתיבת פיקסל חייב לרשם ב- VRAM מידע)
אלא יושב כולו ב- cache גם הוא, מה שאומר שאין כתיבות ל- VRAM. המעבד מצייר את כל הפיקסלים ישירות ב cache עד גמר
הפקת מלוא הפריים כולו, ומשם שולח אותו למסך. החסכון ברובד כתיבה גם הוא מסדר גודל של אלפי מונים.
למעשה באמצעות עבודה ישירה מול cache שמספק את כל הנחוץ כמשטח עבודה לבנייתה של תמונה אחת מלאה,
הורדנו את תעבורת הזכרון הנצרכת מול ה- vram למשהו קטן בסדר גודל ממה שהיה נדרש לפני כן.
כבר מובן מה הגאונות שהדבר הזה מייצר לנו. פרצנו את תקרת הזכוכית של רוחב פס הזכרון, זה שמעיב על מעבדים גראפיים
מאז הולדת התחום הגראפי לפני עשרות שנים, והעברו את הבעיה לתוך השבב עצמו, ששם קל לטפל בה, שם המגבלה כמעט ואינה
קיימת היות והזכרון מטמון גדל בביצועיו במישרין לשפורי הליטוגרפיה עצמה. הללויה.
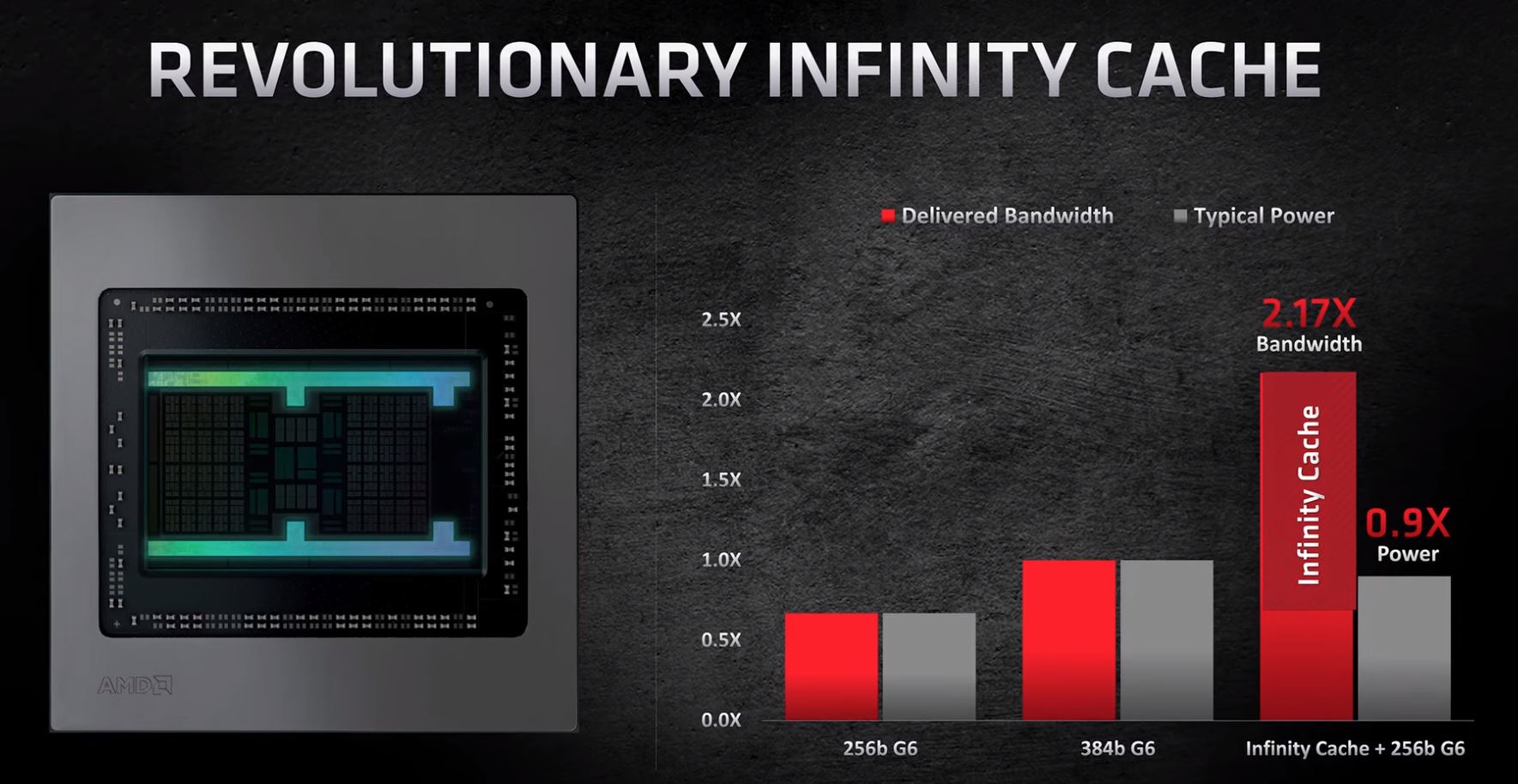
חישובי רוחב פס להבנת העסק:
AMD בחרה בהטמעה הטכנית שלה, כאמור בשבב Navi21, ליישם רוחב פס מטמון של 4096 סיביות. משמע שבכל פעימה
(בכל קלוק) הוא מאפשר כתיבה או קריאה של 4096 סיביות. בגלל שזכרון מטמון עובד בשיטת SDR הוא גמיש יותר מ- DDR ובוודאי
גמיש יותר מכל השיטות שלאחריו, ויכול לבצע כתיבה או קריאה פר קלוק כרצונו. מנגד DDR מחייב כתיבה אחת וגם קריאה אחת,
אך לא שתיים מאותו הסוג. למעשה DDR זה חצי רוחב פס לכל פעולה read/write שמציגים אותם ביחד כחיבור, אך בפועל זה מטעה.
אותן המגבלות חלות גרוע עוד יותר על GDDR5 וכיום GDDR6X. כי שם זה יותר מרק קריאה אחת וכתיבה אחת, זה כמה מכל סוג
ביחס של חצי חצי. אז הנה עוד יתרון של cache שהוא מסוג SDR ולא מוגבל. הוא יכול לנצל את 100% שלו רק לקריאה או רק לכתיבה
ולא נדרש להתפשר על חצי מכל סוג לכל היותר. האמור משפר עוד יותר את התעבורה בפרקטיקה המעשית.
השבב Navi21 מחושב מבחינת רוחב פס, ככזה העובד בתדר עבודה ממוצע טיפוסי מגודל 2150mhz, שאלו 2150 מיליוני קלוקים בשניה.
ולכן רוחב הפס זכרון שנוצר אל מול ה- cache הוא 4096 סיביות כפול 2150 מיליון = 8.8 מיליארד ביטים בשניה.
נחלק ב-8 ונקבל 1.1 מיליארד bytes בשניה או בקיצור, 1100Gbyte לשניה.
רוחב הפס זכרון הכללי של ה- VRAM בכרטיס זה הוא 256 סיביות בתצורת GDDR6 שמשמעותה 16bit per clock per pin.
או במלים אחרות 512GByte בלבד.
אנו רואים שזכרון המטמון למעשה יותר מאשר מכפיל את רוחב פס התעבורה הזמין לליבת המעבד, כעת ליבת המעבד הגראפי
הלכה למעשה רואה כמשטח עבודה, מהירות מטורפת של כ- 1100Gbyte לשניה ועוד מסוג מועדף שכולו SDR.
לשם השוואה, מהירות רוחב הפס של rtx3090 באמצעות 384 ביט זכרון GDDR6X מהיר במיוחד 19.5bit per clock per pin
היא רק 936Gbyte (שמוגבלת כאמור לחצי כתיבה וחצי קריאה בלבד).
קרי הטמעת זכרון מטמון חלוצי זה מאפשר בידי Navi21 לזכות לרוחב פס אפקטיבי גדול עוד יותר משמעותית מזה שיש לכרטיס
הדגל RTX3090. למעשה כרגע המצב הוא, שליבתו של Navi21 מקבלת יותר רוחב פס משהיא מסוגלת לעבד אותו במלוא תפוקתה.
זה שהרוחב פס האמור מוגבל ל- רק 128MB נפח כבר די מובן לקורא, לא ממש מפריעים פה, היות ובכל שלב בעבוד הגראפי על מנת
להשלים את מלוא התמונה, הנפח הזה מספק את צרכי השיטה/הטכניקה שבה פועל עבוד גראפי. הוא לוקח ל- cache את מה שהוא
צריך לתמונה אחת, מבצע את הכל ב- cache, ואז זורק לפח אחרי שסיים את מה שלא צריך. זאת עד להשלמת תמונה אחת שמוכנה
לשדור למסך.
AMD התבקשה לתאר לפנינו מה המקבילה של רוחב הפס הזה לעומת השיטה של פעם (המסורתית), ולכן בנתה את השקף הבא
שמיד נסבירו - גלגלו מטה לאחרי התמונה:
בעמודה השמאלית רוחב פס המתקבל רק באמצעות שמוש מסורתי בשבבי זכרון מסוג GDDR6, ברוחב 256 סיביות, במהירות
16bit per clock per pin, שמייצר רוחב פס 512Gbyte לשניה. כמובן בעמודה האמצעית זה אותו הדבר רק פי אחד וחצי, קרי 384 סיביות,
שמייצר 768Gbyte לשניה.
ובעמודה הימנית הם לקחו את הרוחב פס של הזכרון מטמון מגודל 1100Gbyte בשילוב הפוטנציאל הנוסף שמספק הזכרון הגנרי Vram שהוא
בעצמו 256 סיביות (512Gbyte), יוצא 1100 + 512 = 1612Gbyte סה"כ. ואם נחלק את הערך 1612 בערך של העמודה השמאלית 512
נקבל את היחס שהם כתבו שהוא פי 3 סדר גודל גס.
והנה לנו גאונות, שהיא די טריויאלית ופשוטה להבנה, קיימת למעשה בעולם החישוב והעבודי מאז ומתמיד, זכרון מטמון, שלראשונה בזכות
ליטוגרפיה מספיק מתקדמת, מאפשרת הטמעת cache פרקטי ואפקטיבי דיו לצרכים גראפיים, במעבד גראפי. משהו שלא היה ניתן לבצע
עד שהליטוגרפיה המודרנית נולדה.
מכיון שהשיטה הזו כל כך דרמטית ופורצת דרך מבחינה טכנולוגית ויישומית, היא תאומץ מעתה על ידי כל התעשיה בכלל, נוידיאה ואינטל גם.
היא פשוטה, זולה, אפקטיבית, וקלה למימוש. אין אפשרות להגן עליה גם בפטנט. cache זה cache וזה ישן יותר מכל החברים פה בפורום.
מעתה לא תהיה תלויה עוד טכנולוגיית העבוד הגראפית, במגבלה של השבבי זכרון ורוחב הפס (בסיביות) שממנו מורכב ה- VRAM,
שמעתה יוכל להיות איטי הרבה יותר וזול - קרי להשתמש גם בזכרונות איטיים וזולים להטמעה, ובתנאי שנפח הזכרון cache - מהירותו
וגודלו מספקים ומשלימים את רעבו של המעבד הגראפי, לקצב קריאות וכתיבות המספקים לרנדורה של תמונה בדידה.
בדור הבא של הליטוגרפיה, כנראה 5nm, שיאפשר בעוד שנה שנתיים את הדור כרטיסים הבא, יכפילו את כמות הטרנזיסטורים מאזור
26-28 מיליארד שבו הוא נמצא כיום (26 מיליארד ל- navi21 ו- 28 מיליארד ל- GA102) לאזור 50 מיליארד טרנזיטורים.
במצב שכזה יתאפשר בידי כרטיסי המסך להקצות אף יותר מ- 6 מיליארד טרנסיטורים לטובת זכרון מטמון, כמו למשל 12 מיליארד
טרנזיטורים לטובת זכרון מטמון בגודל 256MB, מרכיב שישפר עוד יותר את גמישות היכולת הסדר וההביצוע שבו המעבד הגראפי עושה
את עבודתו. שכן כשיש לרשותנו כבר 50 מיליארד טרנזיסטורים בשבב, הקצאת 12 מיליארד מתוכם עדיין מותירים 38 מיליארד למרכיב העבודי
של השבב. היחס 12 לעומת 38 הוא יחס סביר. יבצעו בחינה מה האופטימום בהיבט הזה, ביחס שבין cache לכח עיבוד, ובהתאם יחליטו
כמה cache אופטימאלי להקצות במעבד הגרפי.
*ככל שהחברים יבקשו להכנס לדון ולהעמיק בנושא, ו/או להכנס לתחומים שנאמר במאמר ככאלו שלא נרחיב עליהם כעת, תרגישו חופשי
לשאול ולחפור. אעשה כמיטב יכולתי והשכלתי את התחום להשיב ולהרחיב.
**כותב המאמר הינו בוגר מתמטיקה ומדעי המחשב, כאשר אחת מהתמחויותיו בקרירה הינם חישוביות ועבוד גראפי בעולם המחשובי.
-
3
-
3
-
^אתה שופט את העתיד, על סמך הסטוריה ישנה ורחוקה, ותדמית שהדביקו לחברה קקיונית דאז, בכח.
קשה להפטר ממנה ולראיה גם אתה נדבקת.
אבל היום מדובר באנשים אחרים ב- AMD, בצוותים אחרים, הנהגה אחרת, סמנכ"לים התחלפו, כולם אגב,
ומדובר במדיניות אחרת ...
אין טעם למותג בינלאומי בכזה סדר גודל, בשלב כזה של נסיקה חסרת תקדים בהסטוריה של החברה, לשקר
לתקשורת הרי, רק כדי לצאת מגוחכים בעוד שבוע וחצי (שזה מה שאתה חושב שיקרה כן).
שכחת, מדובר היום בחברה שממוצבת במקום אחר לחלוטין, מרחק שמיים מארץ מ- AMD של לפני 8 שנים
שהיתה אז בשפל ובסכנה ממשית להמחק (כדי לשרוד מוכנים לעשות הכל כידוע).
החברה כיום בשווי של 90 מיליארד דולר, שמנייתה מצויה בערך הגבוה ביותר הסטורית (ראה מטה).
כיום היא חברה עם המון אחריות לפרסטיג'ה שבנתה במו ידיה בעמל רב בשנים האחרונות, כל איש PR בחברה יזהיר
את אחרון הסמנכ"לים והמנכ"לית - לבל יעזו לשקר במילימטר. שכן אז גודל ההפסד שיגרם, עולה מאות מונים
בנזקו, על גודל התהילה שהשקר יקנה ל- 5 דקות בערך (עד שהשקר יחשף). יש להם המון מה להפסיד.
סטיות ככל שיהיו בין המדידות שהראו לנו במצגת, לבין המדידות אצל סוקרים צד ג', יהיו בגודל טעות המדידה
הסטטיסטי - שבתעשיה הזו מקובלים להיות מגודל 1-3% . בקיצור זניח על מנת להטות את התוצאה מבחינה
עקרונית ממה שראינו.
הנה לאן שהחברה הגיעה, אין שם טמבלים דיים שיכולים להרוס את התדמית והשם, ולדפוק את אמון המשקיעים,
בדיוק כשהם על הסוס ובשיאם. למען האמת גם לא צריך, יש להם מספיק במה להתגאות מבלי לרמות מאומה.
*יש לך עוד הרבה מה ללמוד חבר יקר, בנהול עסקים ובאסטרטגיה בחברות בינלאומיות מכאלו סדרי גודל.
-
off topic,
כותבים בעברית - מה יעשו "בנדון" (בלי האות יוד).
"נדון" הוא מה שדנים עליו.
"נידון" הוא לדוגמא, אדם הנידון לתליה.
-
ציטוט של oneq
שלום,
טוב אחרי שלשום החלטתי שזהו, אני לא מחכה יותר ומשדרג את המערכת שלי לפלטפורמה עדכנית יותר ( במיוחד שאין לי למה לחכות כי AMD לא הכריזו על רייזן 3 אלא רק רייזן 5 שהוא גם ככה לא בתקציב שלי).
רציתי לשאול 3 שאלות בבקשה:
1, האם תהיה איזושהי הורדת מחירים בעקבות הדור הבא שהולך לצאת, ואם כן האם שווה לחכות עוד קצת עם הקנייה?
2. האם RYZEN 7 2700 הוא יותר Future Proof מאשר RYZEN 5 3600 (בשל העובדה שהוא 8C/16T ולא 6C/12T כמו ה 3600)?
אני לא מתכוון לשדרג שוב מעבד ב-5 שנים הקרובות...
3. מה ההבדל בין 10400F ל-3600?
השימושים הם גיימינג בלבד,
תודה רבה
אני רק שאלת תם, אבל היא אולי השאלה הכי חשובה שכלל לא נשאלה, לא על ידי אף אחד פה, ולא על ידך.
מה היא הפלטפורמה הנוכחית שלך, קרי מה הוא המעבד ?
משוב על שאלה זו ייתן בידנו כוון, להבין, האם המשימה שעבורה בקשת לרכוש מחשב חדש (לוח + מעבד + ואולי גם זכרון ?)
שהיא גיימינג, בכלל מצריכה שדרוג ?
הרבה עושים טעות כבר בסעיף הזה והוא לאבחן לא נכונה, מהי נקודת התורפה במכונה הנוכחית.
על פי רוב וכמעט ברוב רובם המכריע של המקרים, צוואר הבקבוק הוא בכלל כרטיס המסך, ולא הפלטפורמה עצמה (מעבד).
אז בוא נבדוק תחילה יחדיו, מאיזו נקודת מוצא אנו מתחילים את המסע...
-
השפור ב- RT בדור 3000 לעומת דור 2000, הוא לינארי לשפור ביצועים ברסטריזציה.
קרי עם 3080 מהיר ב- X אחוזים מעל 2080ti איפה שאין RT, יצא, שהוא מהיר ממנו באותם X אחוזים, גם במקרים שבהם יש RT.
נוידיאה שמרו לינאריות ויחס כוחות בין רסטרזציה וחישובי RT בין הדורות.
**הטעו אותנו לחשוב אחרת לפני כן, ובגלל זה אנחנו כאילו מתפלאים. אבל אין מה להתפלא. נוידיאה כנראה עשו נכון ומצאו איזוןשהם משמרים אותו.
-
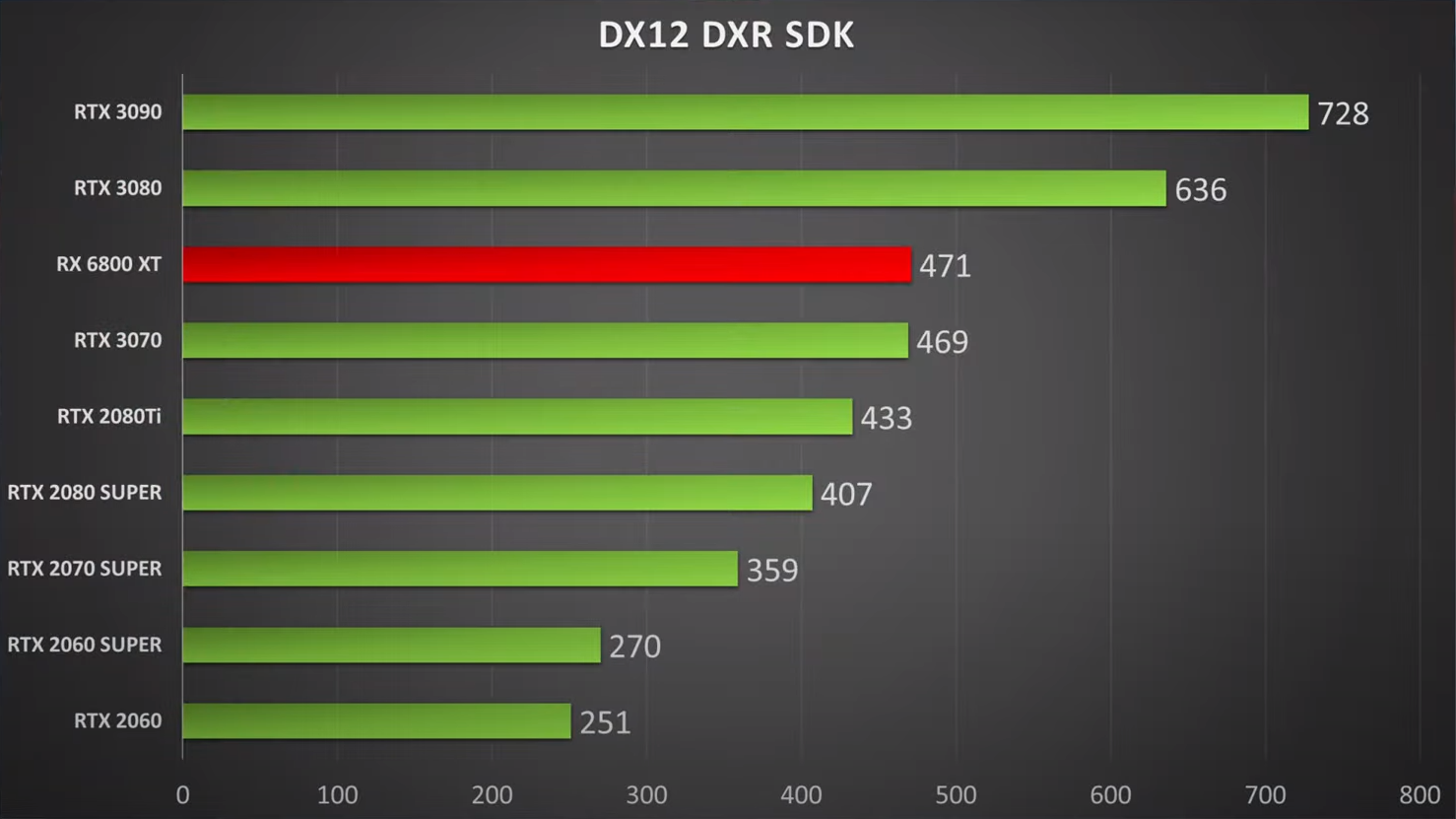
מתחילות לצאת כל מני השוואות צד ג' , שמנסות להעריך את כוחו של RDNA2 בביצועי RT, וזאת משום ש- AMD
כלל לא דברה על זה. אז הנה המידע והוא טרי מעכשיו:
להלן הטבלה כתקציר מנהלים שאומרת לנו איפה הכח היחסי בהשוואה רוחבית בין כל הדגמים:
-
ניתוח יפה:
-
ברמת העקרון האלגוריתמי עדיף כמה שפחות ליבות בהספק שווה ערך. וזה נכון לכל סוגי החישובים, לא רק למשחקים.
אם אפשר לקבל ליבה אחת בלבד, שחוזקה כשל n ליבות חלשות, היא תהיה עדיפה.
ומדוע:
אם יש n טרדים, אז ליבה בודדת בהספק שקול ל- n, תבצע אותו הדבר כמו מעבד שיש לו n לבות הרי.
אבל, אם נכנסים פחות מ- n טרדים, לדוגמא טרד אחד, הוא ירוץ על הליבה הבודדת החזקה,
פי n יותר מהר, מאשר שירוץ על ליבה אחת חלשה (במעבד בעל n הליבות).
לעולם זכרו, עדיף כמה שפחות ליבות, בהספק שווה ערך להרבה לבות.
חלוקת העבוד לכמות לבות היא לא מתוך בחירה - אלא מתוך אילוץ.
משום שיש תקרת ביצועים שניתן לעשות ב- pipe line בודד. ולכן הכניסו עוד לבות כדי בכל זאת לגדול לרוחב,
באם אי אפשר לגדול לגובה.
מעבר לכל זאת, יש אלגוריתמים שלא ניתן למקבל מאומה, ואז על אחת כמה וכמה.
-
כתבת באמצע הלילה, היית בטח גמור מת...
-
^הצחוק של השני החברים שמה מאד סוחף ומעצים את החוויה.
הקטע שבו הוא סיים היה שוס...
בכל אופן החדש של red gaming.... מעניין:
-
כן, רק אתה חושב. יש כותבים מצחיקים יותר ומצחיקים פחות בסדרה.
בכל השקה זה תמיד כיף לראות את היוצרים עושים לקהילה קצת שואו משעשע.
אל תפספס את השלישי שלנקקתי, בספרדית, הוא חזק קצר וקולע...
-
-
עוד כמה בסדרה של הפרודיה :
-
1
-
-
ציטוט של iGodly
ידוע אם ה DLSS של AMD יעבוד גם אם 5700XT או רק בסדרה החדשה?
בשלב הזה עוד לא נאמר לקהילה מאומה. יש להניח שזה יהיה exclusive רק לסדרה 6000...
-
ציטוט של Jabberwock
ללא הקאש מה יעזור? RDNA1 עם קצת יותר זיכרון ושיפור בתדר ? לפחות הבאגים בחומרה יתוקנו
צודק, זו בטח טעות. אז כנראה זה עם cache, או שזה 384bit. אחד מהשניים.
בכל אופן זה משהו מהיר כדי 30% מעל rx5700 ששם אותו למעשה מרחק יריקה מביצועי 2080ti.
400$ מתורגמים למחיר ישראלי (אחרי התיצבות מחירים) בגובה 2000 ש"ח לצרכן.
nice
זו הקטגוריה שיותר מדברת אלי...
כי לאוכל נבלות שכמותי, מה שהמדרגה הזו מאפשרת, זו הוזלה במחירי כרטיסי יד שניה.
שהם למעשה מה שאני מעוניין בו מלכתחילה

ננסח זאת כך:
במצב בו הושק מוצר שמקביל סדר גודל ל- 2080ti, במחיר 400$ לצרכן, שיש לו 12GB זכרון,
שזה 1 יותר ממה שיש ל 2080ti (קרי לא סובל מהתרוץ שצריכים לספק במקרה של 3070 עם ה- רק 8GB)
אז בכמה יוכלו מוכרי יד שניה למכור את 2080ti שלהם ?
נגיד 250-300$ ?
שזה בארץ סביבות 1250-1500 ש"ח לערך בלוח יד 2...
הבנת לאן אני חותר...



פריצת דרך בעולם ההאצה הגראפית - cache
ב כרטיסי מסך
פורסם
מוטב לנפוליאון להתעסק במה שהוא מבין בו, במלחמות וכיבושים, ולא במדעי המחשב, איפה שאין לו נוצות....