חברים מובילים



Popular Content
Showing content with the highest reputation since 08/03/2025 ב הודעות
-
היי סיכוי קלוש עד לא קיים, בטח בתקציב הזה ...2 points
-
שנים אחרי שננטש על שרת מיושן, פרויקט שימור דיגיטלי מחזיר לחיים את פלטפורמת הבלוגים המקומית. המהלך הזה אינו תלוש מהמציאות, אלא משתלב במגמה עולמית שבה משתמשים נוטשים אלגוריתמים לטובת קהילות טקסט אינטימיות ותוכן אנושי לכתבה2 points
-
2 points
-
2 pointsאני דווקא מאוד אוהב את סדרת ה-vivobook של אסוס, איכות מאוד טובה ביחס למחיר (כמובן לא ברמה של ה-zenbook או דגמים אחרים של חברות אחרות שעולות פי-2 או אפילו פי-3 ויותר). מהשירות של אסוס בארץ יש לי חוויות טובות (אחריות עם איסוף והחזרה מבית הלקוח). לגבי הזיכרון שהזכרתם פה, 16GB זה סביר אבל גבולי.. תלוי בשימוש. אבל לא צריך לנחש, פשוט תפתח את ה-task manager ותראה בכמה זיכרון אתה משתמש נכון להיום. לקנות סתם אקסטרה זיכרון זה נחמד אולי לעתיד, אבל מיותר בהווה. זיכרון פנוי זה זיכרון מבוזבז, הוא לא נותן כלום.2 points
-
רישיון למערכת הפעלה כדאי לרכוש ברשת דיגיטלי בפחות מ 100 ש"ח. מארזים - יש בשוק המון , לא מכיר את כולם ולא יודע מה להמליץ מבין הזולים . אני בוחר מארז יקר ( ביחס למפרט ) יש מקום לחסוך 100 ש"ח . זה מארז גדול אבל עם פילטרים ועם גומיות במקומות הנכונים . ספק , בטווח המחיר של עד 200 ש"ח יש הרבה דברים , לא בטוח מי מבניהם עדיף . אף אחד לא עושה לי את זה . מוזמן מאוד לחפש חוו"ד שניה . 32 גיגה זכרון זה בראיה לעתיד , זה הדבר הראשון שאפשר לחסוך בו אם אתה רוצה לשפר את המחיר . במיוחד רלוונטי במפרט של ה 8400F . כרטיס אלחוט פנימי יעלה כ 150-200 ש"ח. כרטיס USB אינו לטעמי . 150-200ש"ח זה ההפרש בין לוח זול ובסיסי מאוד ללוח יותר טוב מכל הבחינות שגם מגיע עם אלחוט , אז לוקחים לוח אם עם אלחוט . לא חייב לרכוש ב TMS , נוח לי לעבוד עם המערכת שלהם . אתה יכול לקחת מפרט מוכן ולהעביר לחנות אחרת , לראות מה הם מציעים ולחזור לפה לוודא שהכל תקין . https://tms.co.il/builds/555086 מערכת דור קודם , אולי למרות הכל שווה להוסיף עוד טיפה למעבד כי גם ככה לוקחים משהו ישן . אבל יעשה את העבודה, אתה לוקח כרטיס מסך פשוט , המעבד לא יעבוד קשה. https://tms.co.il/builds/555003 מערכת עדכנית יותר עם מעבד בסיסי של הדור הזה. יש מצד שאפשר לחסוך הרבה לגבי הזכרון , צריך להתעמק , אולי אפילו לקחת 24 גיגה ( אפשרי כאן ) המעבד הזה יותר חזק, לא בטוח ששווה תוספת של 400 ש"ח למערכת , אני מניח שאם מוסיפים 400 ש"ח למערכת הקודמת אז אפשר לקחת כרטיס מסך עוד יותר חזק ( ועדין לא להגיע ל"עומס יתר" על המעבד ) . https://tms.co.il/builds/555087 ככה הוא יראה עם 24 גיגה של זכרון שהוא בפירוש יותר איטי . העניין הוא שיש מצב סביר שגם עם הזכרון האיטי הוא עדין יהיה יותר מהיר מאשר המחשב המחשב הראשון . זאת שאלה מעניינת שדורשת התעמקות . בשביל האיזון , חנות נוספת . https://startpc.co.il/new-pc/value שני הראשונים הם באותה קטגוריה של המחשב הזול יותר שהצעתי ה SSD יותר קטנים . הלוח ללא אלחוט . הזכרון הוא 16 . המארז יותר זול אבל זה לא אמור שהוא לא מספיק טוב. אפשר לבקש מהחנות להתאים את המפרט לצרכים שלך . אני מניח שאפשר למצוא מפרטים כאלה בעוד חנויות2 points
-
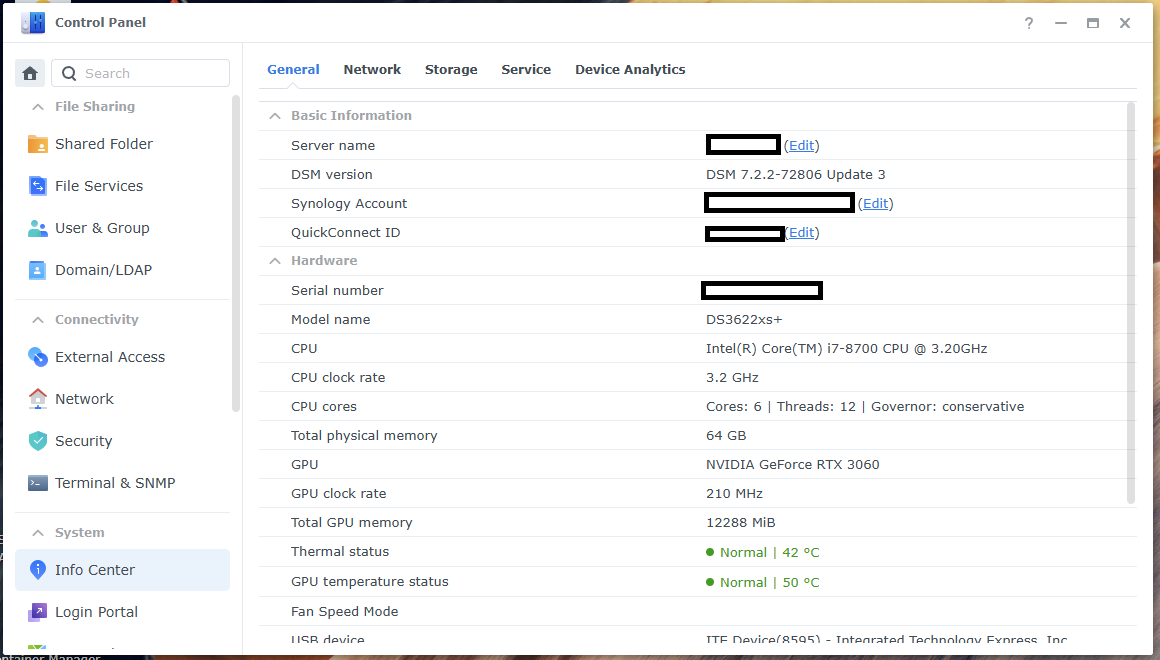
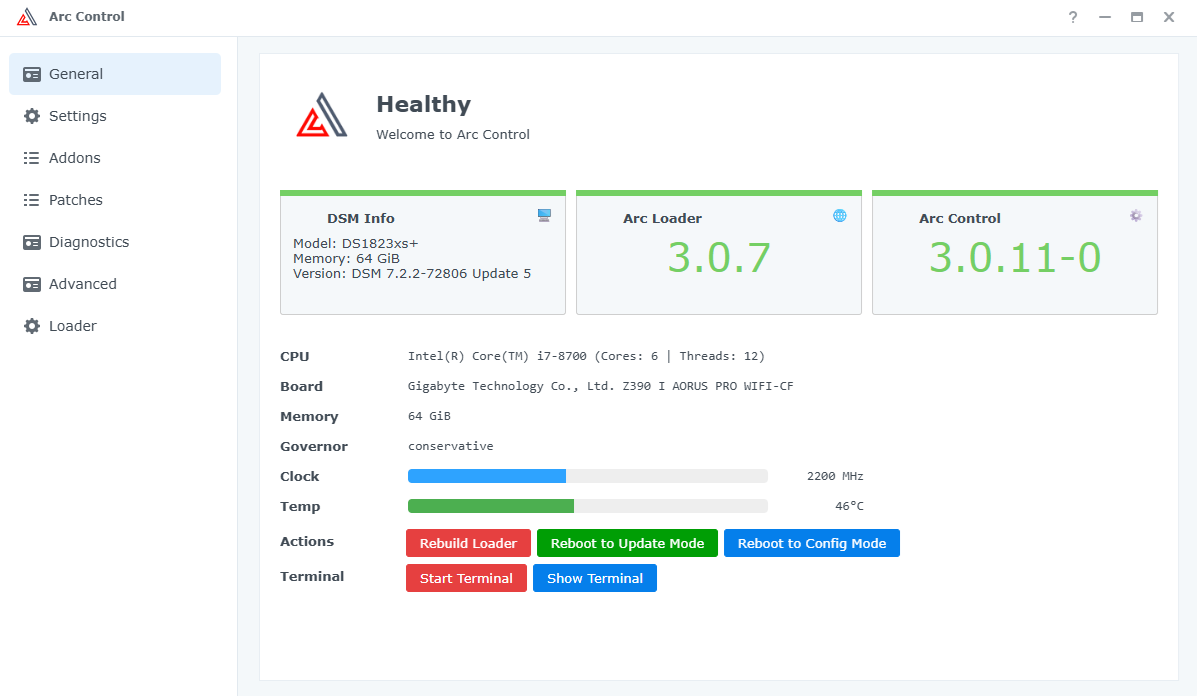
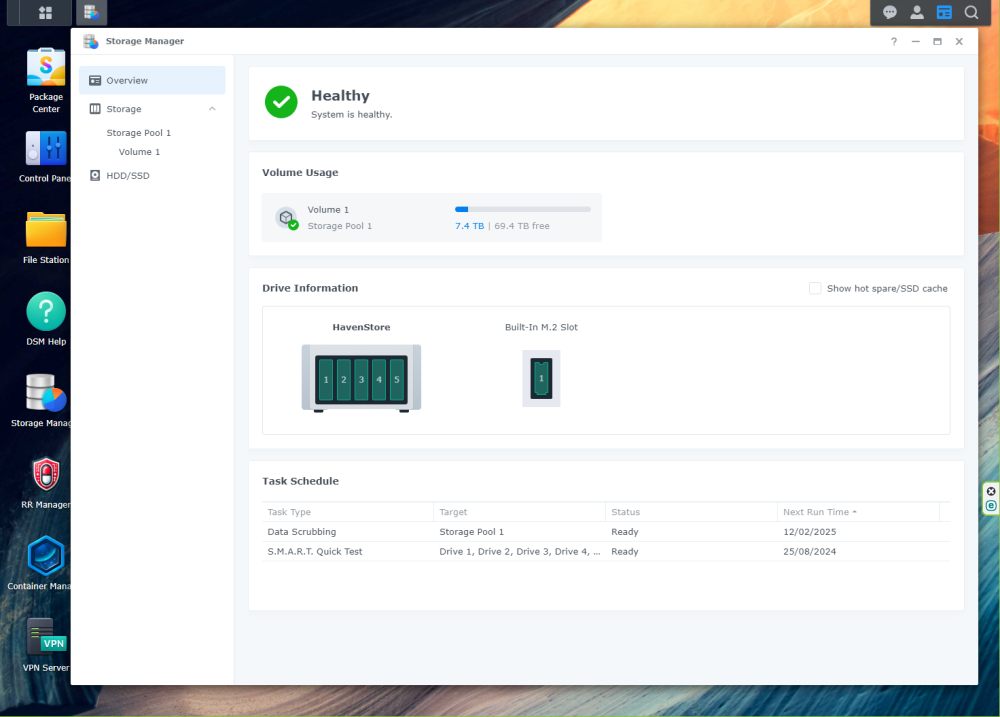
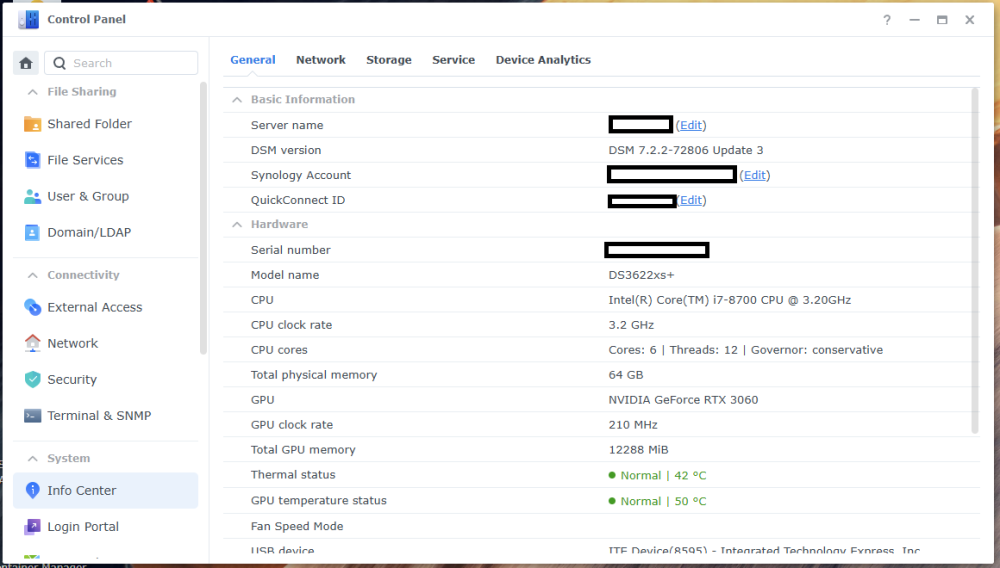
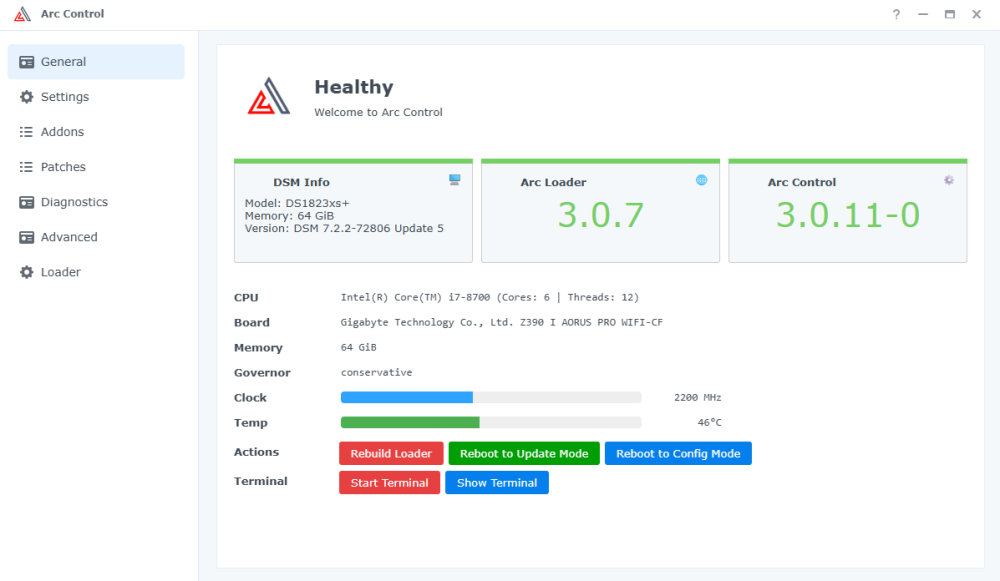
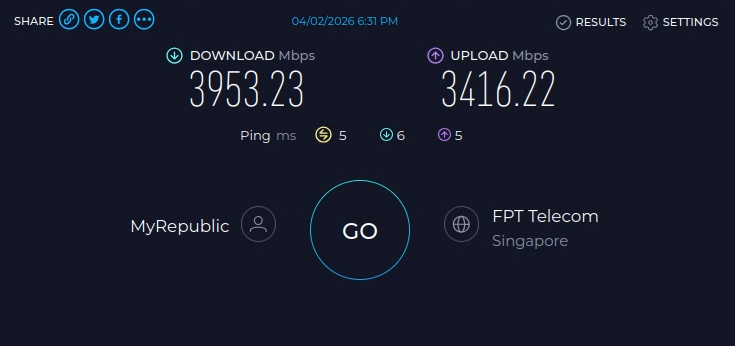
**העדכון בסוף הפוסט** שלום חברים! החלטתי לבנות שרת קבצים פרטי משלי, שהוא בעצם ענן ביתי. אני עושה את זה בחלקים, היות ואני רק בונה את הבסיס קודם (חומרה חלקית, תוכנה ובדיקות), בהכנה לרכישת הדיסקים - בגלל שזו ההוצאה הכי גדולה בסיפור הזה. קודם כל, למי שמתעניין, באופן כללי הבנייה בסרטון הזה של ליינוס דומה מאוד למה שאני עשיתי. זה מקצר תהליכים ומפשט אותם. עם זאת, אני לא רכשתי רכיבים חדשים מהניילון, אלא קניתי משומש איפה שאפשר כדי להוריד הוצאות. כאן הסרטון המקורי של ה-N1: https://www.youtube-nocookie.com/embed/boKmZKTKXHc?feature=oembed הלאה. התחלתי במחשבה לגבי איזו חומרה ואיזה מארז אני צריך בשביל הסיפור הזה, מתוך שיקולים שזה יעלה פחות ממכשיר מסחרי של סינולוג'י (למשל), אבל יאפשר יותר חופש וגמישות. אז קודם התחלתי להסתכל על לוחות קטנים של דור 6/7 של אינטל. כשאני אומר לוחות קטנים, אני מתכוון ל-Mini ITX - שזה לוחות אם שגודלם 17 ס"מ על 17 ס"מ. זה נשמע כלום ושומדבר, אבל זה מכיל את כל מה שצריך בשביל לבנות שרת קבצים, ויותר. הם קיימים כבר הרבה שנים, עובדים עם מוצרי מדף (ספקים, כוננים, מעבדים וכו'), ונותנים תמורה מעולה לכסף. פחות או יותר לכל היצרנים יש סדרה כזו, ויש אפילו לוחות כאלה בקצה העליון והעדכני של ערכת השבבים Z890 של אינטל. הנה דוגמא כזאת, אבל זה ממש OVERKILL למטרה שעבורה התכנסנו (וגם יכול ליצור בעיה במחשב משחקים בגלל המקום המוגבל שלא משאיר הרבה מקום עבור כרטיסי הרחבה/מסך: https://rog.asus.com/motherboards/rog-strix/rog-strix-z890-i-gaming-wifi/ חזרה לענייננו: בדקתי מחירים וזמינות של כל מיני מעבדים ולוחות, ובסוף התכנסתי דווקא לדור שמיני ותשיעי של אינטל. למה? כי הלוחות בדור הזה הם הלוחות האחרונים (שאינם לוחות תעשייתיים) שמאפשרים עד שישה כונני SATA, או חמישה כונני SATA וכונן M.2 יחיד. כל לוח בדורות שאחרי דור תשיעי של אינטל כבר מעדיפים שני כונני M.2 ומשאירים רק ארבעה חיבורים זמינים (או פחות) עבור כונני SATA. זה מבאס, וזה גם עלול לחייב כרטיס הרחבה ליציאות SATA נוספות - דבר שהעדפתי להימנע ממנו (מפני שיש תוכנות NAS שפשוט לא משחקות עם כרטיסים כאלה כמו שצריך). התחלתי לבדוק מחירים וזמינות של לוחות, ובסוף התכנסתי ללוח הזה: ASROCK Fatal1ty Z370 Gaming-ITX/ac 25/02/2025: רכשתי לוח משומש אחר מבוסס Z390, עם ארבע יציאות SATA מובנות, ועוד שני חיבורי M2 (אחד בצד העליון ואחד בצד התחתון) כדי לפתור בעיה של מחסור ביציאות SATA, כפי שאסביר בהמשך. הדגם בו בחרתי הוא Gigabyte Z390 I AORUS PRO WIFI , ומה שנותר זה: מעבד, קירור למעבד, כרטיס מסך (או לחילופין מעבד עם יכולות גרפיות מובנות), ספק מתח מתאים, מארז, וכמובן דיסקים. בשביל המארז בחרתי את המארז הקטנטן (יחסית) שבו משתמש גם ליינוס - JONSBO N1: איכות בנייה טובה מאוד (בעיקר כשמדובר במוצר סיני למהדרין), ותכנון מודולרי שמאפשר להכניס כל מה שצריך ועדיין לשמור על מארז ממש קטנצ'יק. אותו כמובן הזמנתי חדש מעלי אקספרס, ולקח כשבוע שבועיים להגיע אליי. 05/12/2024: השתדרגתי למארז גדול יותר של JONSBO - דגם N3. הדגם הזה מרווח יותר ומכיל עד 8 דיסקים קשיחים 3.5” SATA, ועוד כונן 2.5”. עם זאת, יש לו חסרון מסוים שהוא משמעותי - הוא מקבל רק לוחות ITX. כך נשמר הגודל הקומפקטי שלו. וכשהולכים על לוח ITX, יש הרבה פשרות. בעיקר כיום. בעבר עוד הוציאו יצרניות כמו ASROCK (שהיא יצרנית מוכרת) לוחות ITX איכותיים עם 6 מחברי SATA. אבל כיום הם מספקים כאלה רק בתחום התעשייתי (RACK). כדי למצוא לוחות קטנים עם מספר יציאות SATA גדול על הלוח עצמו, צריך לפנות לשוק הלוחות הלא ממותגים של סין. וזה לא רעיון אידיאלי. למה? מעבר לחוסר האמינות הביטחונית שלהם (סבירות לרוגלה ברמת החומרה), והעובדה שאין להם אבא ואמא שיעזרו עם בעיות לאחר הרכישה, יש איתם בעיות אמינות כמו למשל התחממות יתר, התרסקויות, ואי יציבות כללית. מה שזה אומר לגבי המצב הנוכחי, הוא שצריך להתפשר. או כרטיס מסך (אם רוצים כרטיס מסך למשל עבור מודלים של AI בעיבוד מקומי), או כרטיס יציאות SATA. במקרה שלי, הלכתי על כרטיס מסך RTX 3060, לפחות עד שאצליח למצוא פתרון טוב יותר. לגבי מעבד - פה התלבטתי. בעיקרון דור שמיני ותשיעי של אינטל הם מעבדי COFFEE LAKE שידועים אמנם בביצועים טובים ומהירות שעון גבוהה, אבל גם בטמפרטורות שפחות מתאימות לפרויקט כזה. והאמת היא שעשיתי טעות. במקום ללכת על מעבדי T (כמו למשל i5-8600T או i7-9700T) שהם גרסה מונמכת שעון ודלת מתח (35 וואט) - אבל קשים לאיתור או יקרים מאוד, בחרתי (בהתחלה) במעבד i3-8350K, ואחר כך גם החלפתי אותו במעבד i7-8700K, ולבסוך במעבד i7-8700. אלו מעבדים טובים (לשני יש פשוט יותר ליבות ותהליכים), אבל הם כמעט פי שלוש בצריכת האנרגיה שלהם.. אבל התמקדתי בעיקר במחיר כי כמו שאמרתי, רציתי לשמור על תקציב נמוך יותר מאשר מכשיר של סינולוג'י. הוספתי קירור אוויר בפרופיל נמוך ID-COOLING IS-40X V2: ו.. זהו בערך. יש לי לא מעט דיסקים ישנים - אם כי בנפחים לא גבוהים (בין 2-5 טרה) שבהם אשתמש, ועבור ההתקנה הראשונית (עבור בדיקת תקינות) השתמשתי בכונן SSD M2 SATA ישן שעליו התקנתי חלונות 11 והרצתי בדיקות. ואז מגיעה ההפתעה. הלוח הזה מכיל בקר רשת חוטית של אינטל, ובנוסף מכיל בקר רשת אלחוטית, גם של אינטל בתקן WIFI5 (802.11AC) אבל.. כשהתקנתי חלונות 11 פתאום הוא זיהה לי בקר אחר. בקר רשת אלחוטית של WIFI6 שהתחבר בשמחה לרשת הביתית שלי במהירות של WIFI6. הכצעקתה?? הרי זה רכיב פנימי (וחשבתי שמולחם) של לוח האם! איך זה בכלל אפשרי? ואז נזכרתי שהלוח שקניתי הוא משומש. הגיע מסין, עם ביוס מעודכן להכי עדכני שיש. כפי הנראה מישהו פתח את החלק שבו נמצא הבקר המדובר, והחליף אותו. אם תסתכלו על התמונה של הלוח למעלה, סימנתי עם חץ ירוק את האיזור המדובר, ואפשר לראות שהפחית שמכסה את הבקר לא לגמרי סגורה כמו שצריך. בקיצור, הרווחתי מן ההפקר. לא יודע אם אשתמש ברשת האלחוטית עבור השרת שאני בונה, אבל טוב שיש, וזה בהחלט עזר במהלך ההתקנה שלא הזדקקתי לכבל רשת. אז בואו נעבור על רשימת הקניות: לוח אם: ASROCK Fatal1ty Z370 Gaming-ITX/ac Gigabyte Z390 I AORUS PRO WIFI- לרכישה מעבד (עם יכולות גרפיות): Intel Core i7-8700 Processor - קנייה (מעבד i7-8700T במקום זה) קירור מעבד: קירור אוויר בפרופיל נמוך ID-COOLING IS-40X V2 קירור מארז: שני מאווררים 82 מ”מ שהגיעו עם המארז. הם מתחברים מגנטית. מתאם ליציאות SATA נוספות: M.2 to SATA3.0 Adapter Card 6Gbps High Speed ASM1166 M.2 PCIE to SATA Expansion Card with Smart Indicator M.2 to SATA3.0 Adapter זכרון עבודה: KLEVV 2x32GB DDR4 3200MHz - קנייה (זכרון דומה) כונן מערכת: Intel Optane 512GB + 32GB Cache אחסון: ST22000NM001E Seagate Exos X22 3.5 22TB Enterprise Internal SATA Hard Drive - חמישה דיסקים (5) של 22TB מבית סיגייט - קנייה מארז: JONSBO N3 - קנייה JONSBO N1 - קנייה ספק: FSP DAGGER PRO 650W - קנייה כרטיס מסך: Asus Dual GeForce RTX 3060 V2 OC Edition מתאם USB ל-LAN: WAVLINK USB-C 5 Gigabit Ethernet Adapter WL-NWU341G * אין לי שום אחריות על הלינקים והזמינות שלהם. וגם לא על המחירים. מצאתי דברים דומים ולא תמיד זהים אבל הם יעבדו בצורה דומה ביחד. המחירים גם הם קצת גבוהים יותר ממה שעלה לי כי רכשתי חלק מהחלקים משומשים, וחלק כבר היה לי מקודם. מומלץ מכל הלב לעשות סקר שוק ולנסות למצוא מציאות שיורידו את המחיר. בפירוש לא ללכת רק על מה שזמין מיידית אלא לחפור קצת. כן, שכחתי להזכיר את ספק המתח. קטנטן וחמוד אבל אימתני. בערך רבע מהגודל של ספק ATX רגיל. חמישה כונני 22TB של סיגייט (מצב Factory Recertified 0 Used Time Sealed Pristine 3YR WR מאיביי) נוספו למערכת במקום הדיסקים הישנים ששימשו לבדיקה ואחסון זמני. וכמובן כוננים שונים - סמסונג, WD BLACK, ועוד אחד או שניים. החלק הבא, יגיע כשאקבל כמה דברים קטנים שחסרים (סוללת ביוס להחליף את הסוללה הקיימת שדי לא מתפקדת כמו שצריך, וכבל הארכה למאוורר המארז שפשוט לא מגיע עד הלוח, וכונן המערכת הקבוע שיהיה INTEL OPTANE). אז אתקין את מערכת ההפעלה שכנראה תהיה XPENOLOGY. השרת המורכב נראה ככה: 27/09/2023: שניים מתוך חמישה מהדיסקים המשומשים אותם שמתי, התבררו כתקולים מה שמסביר למה בניית ה-STORAGE POOL נכשלה פעמיים והתארכה עוד ועוד עד שנתקעה. קיבלתי את כל שאר הרכיבים, והתקנתי את מערכת ההפעלה שהיא XPENOLOGY שבעצם מהווה LOADER למערכת ההפעלה של SYNOLOGY. מערכת מעולה אגב עם המון אפשרויות וממשק גרפי מלוטש. מהירות ההעברה המקסימלית ברשת המקומית שלי מוגבלת לכ-115 מגבייט בלבד (זה כ-920 מגהביט שמתקרב לחיבור עצמו שהוא גיגהביט). כדי לנצל את המהירות האמתית של הדיסקים במערכת, אצטרך לעבור לרשת 2.5GBIT ואני לא רואה את זה קורה בקרוב - כי זה דורש החלפת כרטיסי רשת ונתבים. התקנתי גם שרת OPEN VPN על ה-NAS, והגדרתי אותו עם DYNAMIC DNS כך שאני יכול לגשת לאחסון מכל מקום בעולם. כבר בדקתי וזה עובד (לאחר פתיחת פורטים בנתב, והגדרת לקוח מתאים על הטלפון). 26/12/2023: בגלל הרגליות הפגומות של המארז נדפק לי עוד דיסק. כרגע המערכת עובדת אבל במצב CRITICAL כי אין דיסק עודף למקרה של תקלה. אני שוקל לרכוש מערך של דיסקים 22TB, אבל אני צריך לחסוך לזה מספיק כסף קודם (באיזור 1600-1700 דולר באמזון), וגם לוודא שיש לי פתרון קירור טוב יותר למארז. השרת כיבה את עצמו אוטומטית כאשר כונן ה-NVME של אינטל הגיע ל-70 מעלות. ארכוש עבורו קירור פסיבי. התקנתי על השרת LLAMA-GPT שזה צ'אטבוט בקוד פתוח. עובד נהדר, אם כי כל שאלה מעלה את השימוש במעבד ל-95 אחוז (לזמן קצר). רציתי גם להתקין עליו STABLE DIFUSION מקומי, אבל כפי הנראה זה לא עובד הכי טוב בלי כרטיס מסך חזק, וכמובן דרישות החומרה שלו בכללי הן מאוד גבוהות. מעבר לכך, ברשת המקומית שלי, מהירות העברת הקבצים עומד על כ-65 מגהבייט לשנייה. זה לא אידיאלי, כי אני יודע שהיא יכולה להגיע למקסימום של כ-115 מגהבייט (רשת ג'יגהביט), אבל זה עובד בסדר בשביל הזרמת סרטים וכדומה. אשמח להארות והערות. 23/02/2024: החלפתי את הזיכרונות בזוג סטיקים Corsair vengeance LPX 16GBx2 במהירות 3000 מה"צ. זה ממצה את המקסימום שהלוח יכול לקבל מבחינת זיכרון. הסיבה היא שאני מעוניין במרווח נשימה להרצת dockers במקביל. בגלל זה אני גם מחפש מעבד 9900t שיוריד את צריכת המתח ובמקביל ייתן יותר ליבות/תהליכים. 28/02/2024: שכחתי להזכיר, שמסתבר שבלוחות ASROCK יש בעיה מוזרה כזאת שרמקולים אינם מובנים בהם, וגם כאשר מחברים רמקול קטנטן כזה (PC SPEAKER) ללוח, ומפעילים אותו בביוס, הוא נותן צפצוף רק בעלייה ולא ניתן להשתמש בו להתראות בתוך מערכת ההפעלה - במקרה שלי בתוך מערכת ההפעלה הלינוקסית של SYNOLOGY. זה קצת מפריע כי בשביל התראות אני צריך להיכנס לממשק של השרת ולא לקבל חיווי קולי כמו שאני יכול עם לוחות אחרים. 04/05/2024: היום הזמנתי חמישה דיסקים בנפח 22TB כל אחד. למי שמעוניין, קישור הקנייה באיביי: https://www.ebay.com/itm/204520176934 יש לציין שאלה דיסקים מחודשים (Factory Recertified 0 Used Time Sealed Pristine 3YR WR) עם אחריות שלוש שנים מהמוכר בלבד (לא מסיגייט עצמה). כך שיש כאן נטילת סיכון מחושב. עם זאת, המחיר הוא מהטובים ביותר שיש, וזה נותן לי (כמעט) מיקסום של הנפח המתאפשר ב-NAS הזה (חוץ מאשר במקרה שבו הייתי רוכש דיסקים של 24 טרה, וזה היה עולה לי בהרבה יותר). כעת הדאגה שלי היא להתחממות יתר של המארז שאותו קשה לקרר כך או כך.. אלא אם כן אשתמש בשיפצורים מחוץ למארז - שאני לא מתלהב לעשות. מה שכן, אפשרות שתוריד חום היא להחליף מעבד למעבד מסדרת T שחסכונית באנרגיה. עוד הוצאה שכרגע לא ממש רלוונטית. 09/05/2024: קיבלתי את הדיסקים החדשים אתמול. הם הגיעו ארוזים היטב, ובמצב טוב כפי הנראה. עשיתי לכל אחד בדיקה קצרה של תקינות (לא עברה במלואה - אבל כנראה שזה קשור למארז החיצוני בו השתמשתי שלא מסתדר במאה אחוז עם דיסקים בנפחים כאלה. הוא מוגדר כתומך עד 14 טרה אם אני לא טועה), ואז בדיקת תקינות סקטורים לכמה דקות (אם יש תקלות בדיסק הבדיקה תקרוס די מהר). אז איפסתי את מערכת ההפעלה (XPENOLOGY/SYNOLOGY) ב-NAS, כיביתי, ושלפתי את הדיסקים הישנים (לאחר שגם מחקתי את ה-STORAGE POOL שיצרתי עבורם). לאחר מכן התקנתי את הדיסקים החדשים, והפעלתי. תהליך היצירה מחדש של נפח האחסון הוא בשני חלקים. קודם כל יוצרים את ה-STORAGE POOL, ואז את ה-VOLUME. לאחר מכן, הנפח זמין, אם כי המערכת תעשה אופטימיזציה ברקע במשך הרבה מאוד זמן (בהתאם לנפח האחסון במערכת). במקרה שלי צפי האופטימיזציה הוא מעל יממה. ניתן להתחיל להעתיק חומר לתוך השרת גם בזמן האופטימיזציה, אם כי המערכת עלולה להאט. אבל לא במקרה שלי, כי החומרה חזקה. כעת יש לי 80 טרה (או קצת פחות), עם יתרות של דיסק אחד למקרה של כשל. אני מתכוון להריץ את המערכת שבוע כדי לבדוק יציבות ולוודא שהדיסקים אכן תקינים ולא קורסים. יש לציין שהטמפרטורות של הדיסקים, כצפוי, גבוהות. מעל חמישים מעלות. אצטרך למצוא לזה פתרון וכנראה שהוא יהיה חיצוני (מאוורר/ים צמודים לצידו החיצוני המחורר של המארז). 13/05/2024: בניתי את ה"מטען" של XPENOLOGY מחדש (המערכת עולה מכונן USB וניתן לשנות בה הגדרות, כולל דגם, גם לאחר ההתקנה), עם דגם אחר. לפני כן הדגם שבו השתמשתי היה DS923+ ועכשיו DS1522+ כדי לעשות שימוש ביכולות הכרטיס הגרפי המובנה. לא בטוח שזה שינה משהו. 14/05/2024: לאחר ששמתי לב שעם הדגם החדש יש עומס (שימוש מוגבר בזיכרון) והאטה בביצועי הרשת של ה-NAS, חזרתי לדגם הקודם. זה באמת מוזר ולא ברור למה (החומרה של סינולוג'י בין שני הדגמים זהה או כמעט זהה). אבל זה מה יש. אחת מהבעיות שהתגלתה הייתה חוסר תפקוד של לקוח טורנט מול השרת. זה האט את השרת עד זחילה. 18/05/2024: במסגרת פרויקט ביתי אחר (בית חכם) שאני ממשיך לשפר, הוספתי שקע חכם של TUYA עבור שרת ה-NAS. כעת אני יכול לנטר את צריכת החשמל של השרת. בגלל שהצריכה תלויה בעומס על השרת, היא נעה בין 61W-73W בממוצע. זה אכן יחסית גבוה, אבל צפוי לשרת מבוסס מעבד דור שמיני. 10/08/2024: ניסיתי לעבור למטען חדש של XPENOLOGY בשם ARC LOADER - לא עבד. משום מה, מגרסה מסוימת (הן במטען הקיים שלי - RR LOADER והן במטען ARC LOADER), גם אחרי שאני בונה את המטען עם ההגדרות הרצויות, האתחול לא מקבל כתובת מסיבה כלשהי (כנראה לא מצליח לאתחל לתוך מערכת ההפעלה DSM מסיבה כלשהי). מצאתי שהגרסה האחרונה שאיתה המטען עובד (של RR LOADER) היא 24.7.0. פתחתי כבר תקלה אצל המפתח, אבל לא נראה לי שהוא מצליח לאתר את הבעיה. זה לא סיפור יותר מידי בעייתי בינתיים, אבל ככל שגרסאות חדשות של DSM ייצאו, זה עלול להפוך לבעיה. אעדכן אם וכאשר זה יקרה. בינתיים כבר הצלחתי לעבור ל-ARC LOADER עם גרסה חדשה יותר. מאז הוא מעדכן באופן תקין. 14/08/2024: שמתי לב שהמערכת לא מגיבה בצורה תקינה לגישה למידע. אז הרצתי בדיקות על כל הדיסקים בווליום, ומצאתי שאחד מהם תקול (לא עובר בדיקה ממושכת של S.M.A.R.T). אז אני שולח אותו להחלפה תחת אחריות. אדווח כשאקבל את החלופי. בינתיים המערכת עובדת על CRITICAL (הייתה מקונפגת ל-HOT SPARE אחד בלבד), אבל בלי בעיות. 21/08/2024: קיבלתי את הדיסק החלופי במסגרת האחריות. הגיע די מהר (לקח כשבוע מאז ששלחתי את התקול). בדקתי אותו בדיקה מהירה, ואז התקנתי אותו לתוך השרת. לקח כחצי יום לשחזר את הווליום (עדיין אפשר לעבוד איתו תוך כדי), ואני גם מריץ הפעם EXTENDED SMART TEST שלוקח עוד יותר זמן. בנוסף לכך, כאשר עושים REPAIR במערכת SYNOLOGY זה גם עושה DATA SCRUBBING אוטומטית (שזה דומה לדפרגמנטציה), אז זה לקח בערך יום. בכל מקרה, הדיסק נראה תקין ועובד כמו שצריך. צילום מסך של האחסון שלי כרגע: 28/08/2024: סינולוג'י (יצרנית ה-NAS עליהם מבוסס שרת הקבצים שלי) הוציאה את עדכון 7.2.2 למערכת ההפעלה (DSM) שלה. ההבדל הגדול הוא ביטול יכולת ה-TRANSCODING, ואפליקציית ה-VIDEO STATION. בנוסף לעדכוני אבטחה נחוצים. הסיבה (בין השאר) שהם נתנו לכך היא שרוב המכשירים שמזרימים מדיה כיום משרת NAS מכילים חומרה חזקה יותר מאשר זו של השרת ומסוגלים לפענח את קידודי הווידאו בעצמם. (טאבלטים, מזרימי מדיה, אפילו טלוויזיות חכמות) עם זאת, אני לא ממהר לעדכן לגרסה החדשה של מערכת ההפעלה שלהם. כשיש עדכון כזה רציני, יכולים לצוץ כל מיני באגים ובעיות. עדיף לחכות ולראות. בנוסף, ביטול יכולות זה לא כזה להיט. 23/10/2024: עדכנתי את המטען (LOADER) של השרת, ובאותה הזדמנות גם עדכנתי את מערכת ההפעלה עצמה לגרסה 7.2.2. יש לציין שהגרסה החדשה מורידה יכולת TRANSCODING משרתי סינולוג'י שתמכו בה חומרתית. לפי סינולוג'י, הסיבה היא שרוב מכשירי הקצה כיום (טלפונים, טבלטים, טלוויזיות, מחשבים) כבר מסוגלים לפענח את קידוד הוידאו בקלות בצד שלהם, וכך הם מורידים עומס מהשרת עצמו. לומר שזה לגמרי הגיוני? לא. כי זה פוגע ביכולות מסוימות של השרת. הם יכלו באותה מידה להציע אפשרות תוכנתית לכבות או להפעיל את היכולת. אבל בחרו שלא. עם זאת, העדכון כולל עדכוני אבטחה, והיות ואני ממילא לא צריך TRANSCODING, בחרתי (לאחר כחודש) לעדכן. 11/11/2024: חזרתי מחופשה ביפן, ולצערי השרת לא הצליח לאתחל כמו שצריך. כלומר, לא בכלל. לאחר איפוס ביוס כמה פעמים הוא הצליח לעלות, אבל רק כדי להתרסק לאחר כמה דקות של עבודה. קשה לי לומר מהי הסיבה אבל חששתי שמדובר בלחות/חלודה היות והוא ממוקם ליד חלון ומזג האוויר כאן סוער לפרקים ולח כל הזמן. היות והוא היה מכובה כל התקופה, לא הייתה לו אפשרות לרוץ ולייבש לחות. לפני שקיללתי את מר גורלי והלכתי להזמין לוח אם חליפי (ולא זול), החלטתי לפרק את כל המערך (את לוח האם מהמארז, את האיוורור ואת המעבד והזכרונות) ולהרכיב הכול מחדש לאחר ניקוי מאבק והתזת ספריי מגעים. זה לא משהו שאני שש לעשות כי מדובר במארז קטנטן וצפוף מאוד עם גישה מינימלית לכל מחבר ומחבר. אבל.. לאחר פירוק והרכבה כולל את המעבד עם משחה טרמית מחדש, הצלחתי להחיות את החולה. בינתיים הוא רץ כבר מעל 12 שעות ללא בעיה מיוחדת (כן היה כיבוי טרמי היות וה-NVME הגיע לטמפרטורה גבוהה לאחר שנאלצתי להסיר גוף קירור שלו שפשוט לא נשאר מודבק). אני מזמין גם סוללת ביוס חדשה ליתר ביטחון. 05/12/2024: בשעה טובה, החלפתי מארז וגם הוספתי כרטיס מסך לצורך הרצת מודלים של AI מקומית. הם כבר רצים גם ללא כרטיס המסך, אבל באיטיות משוועת והתחממות משמעותית של השרת. המארז החדש הוא N3 של JONSBO, והכרטיס החדש הוא Asus Dual GeForce RTX 3060 V2 OC Edition. לצערי הכרטיס שבק חיים עוד לפני שנכנס למארז, כך מסתבר. 07/12/2024: הזמנתי מעבד חסכוני יותר באנרגיה (i9-9900T) שיוסיף ליבות ויוריד את צריכת החשמל. עם זאת, שכחתי להזכיר, שלמרות שכרטיס המסך מותקן, הוא לא פעיל בגלל שאני לא מוצא את כבל ה-PCIE שהיה אמור להגיע עם הספק (סביר להניח שהוא קבור איפשהו, אבל לא הצלחתי למצוא אותו בינתיים). לכן הזמנתי כבל מקורי מהיבואן, אבל זה יקח שבועות ארוכים עד שיגיע. חשבתי גם להסיר את ה-SSD CACHE ואז להתקין PROXMOX ולהעביר את מערכת ההפעלה של ה-NAS למכונה וירטואלית, מה שיאפשר להריץ דברים אחרים בנפרד מה-NAS. אבל זה נראה לי פרויקט גדול לזמן אחר. (והרבה התעסקות עם שורת פקודה של לינוקס שאני לא הכי אוהב) 09/12/2024: אז קודם כל, המארז הפתוח מלמעלה. כפי שאפשר לראות, ה-N3 מכיל את הספק בחלק העליון שלו, מה שיוצר צפיפות מצד אחד, אבל מקום לכרטיס מסך רציני יותר מ-LOW PROFILE עבור סלוט יחיד: ואז החלק התחתון של המארז מוגן במכסה מגנטי שהוסר ומאפשר לגשת ולראות את מפרצי הכוננים, שכרגע מכילים רק חמישה מתוך שמונה דיסקים אפשריים, אם כי ייקח לי זמן להבין איך אני יכול לעשות את זה עם כרטיס מסך שתופס לי את חריץ ה-PCIE היחיד, וחריץ M2 יחיד שכבר תפוס: 13/12/2024: הזמנת המעבד בוטלה - לא על ידי, אלא על ידי החנות שהתעכבה במשלוח. בינתיים אשאר עם מה שיש לי. 11/01/2025: לאחר כרטיס מסך משומש אחד שהגיע (כפי הנראה) שרוף, וקשיים לא קטנים בזיהוי הכרטיס החדש (GeForce RTX™ 3060 WINDFORCE OC 12G) על ידי לוח האם של השרת שלי (התחלתי לחשוב שאולי הוא שורף כרטיסי מסך…), הצלחתי להתקין וגם לגרום לשרת לזהות אותו כמו שצריך. המטרה הייתה ונשארה להאיץ דוקרים שיכולים להשתמש בשירותים של כרטיסי מסך. וזה בדיוק מה שאני עושה. אני מריץ OLLAMA (LLM) על השרת, וכרטיס המסך מאפשר לי להאיץ את התגובה של המודלים. 16/01/2025: הצלחתי להתקין סוף סוף את STABLE DIFFUSION WEBUI על השרת שלי. זה מצליח רק דרך שורת פקודה לצערי, ולא ב-PORTAINER שזו דרך הרבה יותר נוחה וקלה להתקין קונטיינרים על לינוקס. זה כמובן גם השרת הכבד ביותר שרץ על ה-NAS, ואוכל בין 15-25 אחוזים מהזכרון.. צירפתי כאן למטה כמה דוגמאות שיצרתי באמצעות טקסט לתמונה. תודות לאתר CIVITAI.COM על הפרומפטים וההגדרות (גם אם שיניתי מעט מהן): 12/02/2025: עדכון קצרצר - הכול עובד (לאחר שהתרסק לי אחרי משחק לא מכוון עם הגדרות הלינוקס), אבל מערכת הלינוקס של השרת חסרה למדי. אין כלים מסוימים שמותקנים כברירת מחדל בהתקנות לינוקס מסודרות, וגם קשה יותר להגדיר PATH קבוע, מה שיוצר בעיות להתקנות דוקרים (קונטיינרים) ובכלל. עם זאת, כרטיס המסך מסייע לדוקרים שפשוט היו זזים הרבה יותר לאט בלעדיו, או שבכלל לא עובדים. בנוסף, המחסור ביציאות SATA נוספות מטריד אותי, כי רכשתי את המארז בשביל יכולת ההרחבה, ומה הטעם, אם התקנת כרטיס מסך כבר עוצרת אותי מהוספת יציאות SATA? מה שכן, אני לומד יותר ממה שרציתי על לינוקס ואיך לינוקס עובד. ובהערת צד, כל פעם שאני מריץ קונטיינר כמו זה שיצר את התמונות היפות למעלה, צריכת החשמל של השרת קופצת מ-70-80 וואט ל-200 וואט ומעלה. זה עדיין מספר נמוך יחסית לשרת, אבל מספר גבוה עבור שרת ביתי קטן. 25/02/2025: רכשתי לוח משומש אחר של גיגהבייט מבוסס ערכת השבבים Z390 של אינטל, עם מעבד טיפה חלש יותר (אותו מספר ליבות אבל מהירות שעון נמוכה יותר וצריכת חשמל נמוכה יותר), וגם מתאם M2 לשש יציאות SATA. זה פותר לי את כל הבעיות שהזכרתי. מאפשר לי להמשיך להשתמש בכרטיס המסך, וגם לחבר עד 10 דיסקים קשיחים במקביל (ארבעה ללוח עצמו, ועוד שישה דרך המתאם). מה שכן, השימוש במתאם (ואולי בלוח החדש) צורך יותר מתח מאשר שיערתי. השרת במנוחה צורך כ-80 וואט לעומת כ-70-73 וואט קודם. אבל החלפת כל החומרה והרכבתה מחדש עברו בשלום. הדבר היחיד שנאבקתי בו (משום מה), היה קשור לכתובת ה-IP אותה השרת מקבל. לאחר שינויי הגדרות שונים, אתחול השרת כמה פעמים וגם הנתב פעם אחת, הכול הסתדר. 13/04/2025: וידאתי שהשרת עובד יפה גם מרחוק (מאוד) ואני יכול לגשת ולהשתמש בשירותים השונים שפתחתי לשימוש חיצוני, ללא בעיות. 28/04/2025: לאחר אחד מהעדכונים, אחד מהשירותים שאני מריץ על השרת (GPT4FREE) הפסיק לעבוד עם תקלת INTERNAL SERVER ERROR שנראה שהיא קשורה להרשאות, אבל אירעה רק לאחר אחד מהעדכונים האוטומטיים, ולא הצלחתי לפתור אותה גם לאחר מחיקה של הדוקר והגדרתו מחדש (כולל משיכת IMAGE). בנוסף, יצאו דגמים חדשים של סינולוג'י, לשנת 2025, שמביאים "בשורה" לא הכי טובה - נעילת דגמי הדיסקים הקשיחים לכאלה שמותגו מחדש ונמכרים תחת שמה של סינולוג'י. עולם ה-NAS לא ממש מבין את ההחלטה הזאת, היות והיא מגבילה את הקונים, ופוגעת בגמישות של סדרות ה-NAS - שלא לדבר על המחיר והזמינות. במקרה שלי זה לא רלוונטי, כי המטען שבו אני משתמש עוקף את המגבלות הללו בדומה לתמיכה שלו כמעט בכל חומרת PC שיש. 06/05/2025: הבעיה הראשונית עם G4F נפתרה - הייתה קשורה להרשאות ולתיקיית COOKIES שעשתה בעיות. אבל גם אחרי התקנה והגדרת הרשאות מחדש, עדיין יש בעיות עם שמירת API KEYS. אני מנסה לפתור את זה מול המפתחים. בנוסף, הגדלתי את כמות הזכרון בשרת למקסימום שהלוח יכול לקבל - 64GB. 17/06/2025: עסקה מעניינת עבור כונן קשיח בנפח 24 טרהבייט, משומש אבל עם 0 סקטורים פגומים ו-5 שנות אחריות - Seagate ST24000NM000H 24TB 7200RPM SATA 6Gb/s 256MB 3.5in. Enterprise Hard Drive וכמובן, כונן קשיח בנפח 22 טרהבייט מהמוכר שממנו קניתי, גם באיביי, עם שלוש שנות אחריות שכבר החליף לי דיסק במסגרת האחריות הזאת: ST22000NT001 Seagate Ironwolf Pro 22TB 3.5 256M Internal SATA Hard Drive המחירים של המוכר ממנו אני רכשתי עלו משמעותית מאז שאני קניתי (ביותר ממאה דולר ליחידה), והמוכר שממנו אני קניתי ממוקם בהונג קונג, ולא היו לי עלויות משלוח. המוכר החדש ממוקם באמריקה, ויש עלות משלוח מסוימת. 08/07/2025: רציתי לעדכן משהו שיכול להיות רלוונטי לבוני NAS - בין אם התקנתם TRUENAS, UNRAID, או XPENOLOGY כמוני. וזה מערכת ה-DOCKER (בסינולוג'י היא מבוססת על אפליקציה פנימית שנקראת CONTAINER MANAGER, וניתן לנהל אותה עם דוקרים שונים לניהול.. דוקרים (כמו פורטיינר למשל). במערכות NAS אחרות יש אפליקציות אחרות שאני לא מכיר. DOCKERS הם מעין קפסולות, או מערכות הפעלה בקופסה, בדומה למכונות וירטואליות. ההבדל הוא שמכונות וירטואליות מדמות את כל חלקי המחשב, ודוקרים משתמשים ישירות במשאבים של השרת המארח. זה מפשט עניינים, ומקל על הרצת מערכות הפעלה שונות ומגוון (מאוד) רחב של אפליקציות ייעודיות. להלן רשימה של הקונטיינרים (הקפסולות שמורצות בתוך הדוקרים) שאני מריץ: Coturn - שרת סיגנלים שמיועד להכוונת וידאו בפורמט WEBRTC (בלעדיו אי אפשר להריץ ווידאו קונפרנס כמו שצריך) Stable Diffusion Forge - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה G4F - ממשק המתחבר לשירותי בינה מלאכותית לצ'אט ויצירת תמונה ברשת ומרכז את כולם במקום אחד HomeAssistant - אפליקציה לניהול בית חכם InvokeAI - בינה מלאכותית לייצור תמונות מטקסט. מתעדכנת וקלה יותר לשימוש Jackett - דוקר לחיפוש טורנטים במגוון מנועי חיפוש. מיועד בעיקר לחיפוש אוטומטי של סדרות וסרטים בשילוב עם Sickchill (למשל) Krita - עורך תמונות בדומה לפוטושופ. קיימת גם עבור חלונות. יש לשים לב שכדי להריץ את פונקציות ה-AI של האפליקציה (בדומה ל-FIREFLY של ADOBE), צריך להתקין את תוסף ה-AI, וגם דוקר מתאים (COMFYUI) MKVToolNix - כלי שמאפשר עריכת קבצי MKV בלי קידוד מחדש. אפשר להוסיף ולהסיר פסי קול, פסי וידאו, וכתוביות. ComfyUI-Nvidia - דוקר להרצת יצירת תמונות ווידאו ב-AI בעזרת כרטיס גרפי Mirotalk P2P - שיחות וידאו אודיו וצ'אט. מתוחכם ועובד מכל דפדפן. כולל כמובן טלפונים ניידים. Navidrome - ניהול אוסף מוסיקה, כולל עדכון אוטומטי של תמונות אלבום, מידע, וכמובן נגן מובנה ותמיכה באפליקציה לטלפון. Ollama + OpenWebUI - אפליקציה מובילה לצ'אט בינה מלאכותית מקומי. משתמש בכרטיס מסך אם כי יכול לעבוד גם עם מעבד בלבד. Text-Generation-WebUI - אפליקציה נוספת לשימוש עם מודלים לצ'אט בינה מלאכותית מקומי. יותר מסובך לעבוד איתו, אבל יותר מהיר ומאפשר חיפוש רשת קל יותר. Stable Diffusion reForge - עוד בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה. SD.Next - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה SearXNG - מנוע חיפוש מקומי שמשלב חיפוש במספר מנועים גלובליים (משמש גם עבור OLLAMA לחיפוש רשת) SwarmUI - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה - משתמש ב-COMFYUI כמנוע היצירה WatchTower - דוקר קטן שמעדכן אוטומטית את כל הדוקרים שמותקנים לגרסה האחרונה Whisper WebUI - אפליקציה להמרה מדיבור לטקסט. משמשת בעיקר לחילוץ כתוביות לסרטים וסדרות. מאפשרת גם תרגום. Zonos - כלי AI לייצור קול מטקסט, עם יכולת חיקוי קולות (VOICE CLONING) במגוון שפות, ומתן גוון רגשי Zonos Hebrew - כלי AI לייצור קול מטקסט, עם יכולת חיקוי קולות (VOICE CLONING) בעברית בלבד (הממשק באנגלית) Kavita - שרת לאירוח קבצי ספרים אלקטרוניים (e-books), אותם אפשר לקרוא מכל מקום, באפליקציה או בדפדפן. Komga - שרת לאירוח קבצי ספרים אלקטרוניים (e-books), אותם אפשר לקרוא מכל מקום, באפליקציה או בדפדפן. AudioBookShelf - שרת לאירוח קבצי ספרים קוליים (audiobooks) להם אפשר להקשיב מכל מקום, באפליקציה או בדפדפן. WPS Office - דוקר של אפליקציות דמויות אופיס (וורד, אקסל, פאוורפוינט וכדומה) LibreOffice - דוקר של אפליקציות אופיס עם אפשרות לתוספים רבים, ביניהם חיבור ל-OLLAMA לעריכה ותוספת טקסט באמצעות בינה מלאכותית Portainer - זו פלטפורמה לניהול דוקרים וקונטיינרים. היות והיא יושבת על בסיס של אפליקציית דוקר קיימת, היא רצה בעצמה על דוקר. מקלה על ניהול הדוקרים ושינוי פרמטרים שלא דרך שורת פקודה (טרמינל). לסיום, הערה קטנה: יש דוקרים ש"אוכלים" הרבה משאבים, גם כשלא עושים בהם שימוש אלא הם סתם רצים ברקע. לכן חלק מהדוקרים ברשימה מכובים, אך אני יכול להפעיל אותם תוך דקות. בנוסף לכך, לא כל הדוקרים שלי פתוחים לשימוש מבחוץ. אלה שכן מוגנים כך שלא כל מי שיש לו סורק כתובות IP יוכל להכנס ולעשות שימוש בהם איך שהוא או היא ירצו. 14/08/2025: רשימת הדוקרים עודכנה. הסרתי את WPS OFFICE בגלל שהוא לא מצליח להתחבר לשרת OLLAMA שלי, והתקנתי את LIBREOFFICE במקומו. ComfyUI-Nvidia מאפשר לי ייצור תמונות וגם וידאו במקום אחד, כולל הגדלת תמונות, ותוספת ומניפולציה של תמונות. כמו כן הוא מתחבר ל-KRITA ונותן לי פתרון מקביל לפוטושופ עם בינה מלאכותית, אבל חינמי. Kavita מיועד לאירוח וארגון קבצי ספרים אלקטרוניים (e-books), ו-AudioBookShelf לאירוח וארגון קבצי ספרים קוליים (Audiobooks). 19/09/2025: הוסרה KAVITA מהרשימה, ונוספו KOMGA, ZONOS, ZONOS HEBREW, TEXT-GENERATION-WEBUI, MKVTOOLNIX 27/10/2025: הוספתי דוקר (לא הכי יציב בעולם) של ניגון רשימות IPTV (טלוויזיה בשידור חי). בנוסף התקנתי מתאם USB ל-5 Gigabit והגדרתי אותו (לא יכול כרגע לבדוק מהירות כי אין לי חיבור במהירות דומה). זאת הרשימה הנוכחית: Coturn - שרת סיגנלים שמיועד להכוונת וידאו בפורמט WEBRTC (בלעדיו אי אפשר להריץ ווידאו קונפרנס כמו שצריך) Stable Diffusion Forge - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה G4F - ממשק המתחבר לשירותי בינה מלאכותית לצ'אט ויצירת תמונה ברשת ומרכז את כולם במקום אחד HomeAssistant - אפליקציה לניהול בית חכם InvokeAI - בינה מלאכותית לייצור תמונות מטקסט. מתעדכנת וקלה יותר לשימוש Jackett - דוקר לחיפוש טורנטים במגוון מנועי חיפוש. מיועד בעיקר לחיפוש אוטומטי של סדרות וסרטים בשילוב עם Sickchill (למשל) Krita - עורך תמונות בדומה לפוטושופ. קיימת גם עבור חלונות. יש לשים לב שכדי להריץ את פונקציות ה-AI של האפליקציה (בדומה ל-FIREFLY של ADOBE), צריך להתקין את תוסף ה-AI, וגם דוקר מתאים (COMFYUI) MKVToolNix - כלי שמאפשר עריכת קבצי MKV בלי קידוד מחדש. אפשר להוסיף ולהסיר פסי קול, פסי וידאו, וכתוביות. ComfyUI-Nvidia - דוקר להרצת יצירת תמונות ווידאו ב-AI בעזרת כרטיס גרפי Mirotalk P2P - שיחות וידאו אודיו וצ'אט. מתוחכם ועובד מכל דפדפן. כולל כמובן טלפונים ניידים. Navidrome - ניהול אוסף מוסיקה, כולל עדכון אוטומטי של תמונות אלבום, מידע, וכמובן נגן מובנה ותמיכה באפליקציה לטלפון. Ollama + OpenWebUI - אפליקציה מובילה לצ'אט בינה מלאכותית מקומי. משתמש בכרטיס מסך אם כי יכול לעבוד גם עם מעבד בלבד. Text-Generation-WebUI - אפליקציה נוספת לשימוש עם מודלים לצ'אט בינה מלאכותית מקומי. יותר מסובך לעבוד איתו, אבל יותר מהיר ומאפשר חיפוש רשת קל יותר. Stable Diffusion reForge - עוד בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה. SD.Next - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה SearXNG - מנוע חיפוש מקומי שמשלב חיפוש במספר מנועים גלובליים (משמש גם עבור OLLAMA לחיפוש רשת) SwarmUI - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה - משתמש ב-COMFYUI כמנוע היצירה WatchTower - דוקר קטן שמעדכן אוטומטית את כל הדוקרים שמותקנים לגרסה האחרונה Whisper WebUI - אפליקציה להמרה מדיבור לטקסט. משמשת בעיקר לחילוץ כתוביות לסרטים וסדרות. מאפשרת גם תרגום. Zonos - כלי AI לייצור קול מטקסט, עם יכולת חיקוי קולות (VOICE CLONING) במגוון שפות, ומתן גוון רגשי Zonos Hebrew - כלי AI לייצור קול מטקסט, עם יכולת חיקוי קולות (VOICE CLONING) בעברית בלבד (הממשק באנגלית) Kavita - שרת לאירוח קבצי ספרים אלקטרוניים (e-books), אותם אפשר לקרוא מכל מקום, באפליקציה או בדפדפן. Komga - שרת לאירוח קבצי ספרים אלקטרוניים (e-books), אותם אפשר לקרוא מכל מקום, באפליקציה או בדפדפן. AudioBookShelf - שרת לאירוח קבצי ספרים קוליים (audiobooks) להם אפשר להקשיב מכל מקום, באפליקציה או בדפדפן. WPS Office - דוקר של אפליקציות דמויות אופיס (וורד, אקסל, פאוורפוינט וכדומה) LibreOffice - דוקר של אפליקציות אופיס עם אפשרות לתוספים רבים, ביניהם חיבור ל-OLLAMA לעריכה ותוספת טקסט באמצעות בינה מלאכותית Portainer - זו פלטפורמה לניהול דוקרים וקונטיינרים. היות והיא יושבת על בסיס של אפליקציית דוקר קיימת, היא רצה בעצמה על דוקר. מקלה על ניהול הדוקרים ושינוי פרמטרים שלא דרך שורת פקודה (טרמינל). ViniPlay - מיועדת לניגון IPTV. ספציפית רשימות M3U או לינקים ישירים בפורמט TS. לא מכילה רשימות (צריך למצוא לבד). 17/11/2025: הוספתי דוקרים של CHANGEDETECTION (לבדיקת שינויים באתרים ברשת - בדומה למה שעושה האתר VISUALPING), docker-cron-restart-notifier שמטרתו לאתחל דוקרים בזמנים מוגדרים מראש, וגם NETALERTX שמנטר את חיבורי הרשת בתוך הרשת הביתית שלי (כך אפשר לראות אם מתחברים משתמשים לא מורשים, למשל). זו הרשימה הנוכחית: Coturn - שרת סיגנלים שמיועד להכוונת וידאו בפורמט WEBRTC (בלעדיו אי אפשר להריץ ווידאו קונפרנס כמו שצריך) Stable Diffusion Forge - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה G4F - ממשק המתחבר לשירותי בינה מלאכותית לצ'אט ויצירת תמונה ברשת ומרכז את כולם במקום אחד HomeAssistant - אפליקציה לניהול בית חכם InvokeAI - בינה מלאכותית לייצור תמונות מטקסט. מתעדכנת וקלה יותר לשימוש Jackett - דוקר לחיפוש טורנטים במגוון מנועי חיפוש. מיועד בעיקר לחיפוש אוטומטי של סדרות וסרטים בשילוב עם Sickchill (למשל) Krita - עורך תמונות בדומה לפוטושופ. קיימת גם עבור חלונות. יש לשים לב שכדי להריץ את פונקציות ה-AI של האפליקציה (בדומה ל-FIREFLY של ADOBE), צריך להתקין את תוסף ה-AI, וגם דוקר מתאים (COMFYUI) MKVToolNix - כלי שמאפשר עריכת קבצי MKV בלי קידוד מחדש. אפשר להוסיף ולהסיר פסי קול, פסי וידאו, וכתוביות. ComfyUI-Nvidia - דוקר להרצת יצירת תמונות ווידאו ב-AI בעזרת כרטיס גרפי Mirotalk P2P - שיחות וידאו אודיו וצ'אט. מתוחכם ועובד מכל דפדפן. כולל כמובן טלפונים ניידים. Navidrome - ניהול אוסף מוסיקה, כולל עדכון אוטומטי של תמונות אלבום, מידע, וכמובן נגן מובנה ותמיכה באפליקציה לטלפון. Ollama + OpenWebUI - אפליקציה מובילה לצ'אט בינה מלאכותית מקומי. משתמש בכרטיס מסך אם כי יכול לעבוד גם עם מעבד בלבד. Text-Generation-WebUI - אפליקציה נוספת לשימוש עם מודלים לצ'אט בינה מלאכותית מקומי. יותר מסובך לעבוד איתו, אבל יותר מהיר ומאפשר חיפוש רשת קל יותר. Stable Diffusion reForge - עוד בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה. SD.Next - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה SearXNG - מנוע חיפוש מקומי שמשלב חיפוש במספר מנועים גלובליים (משמש גם עבור OLLAMA לחיפוש רשת) SwarmUI - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה - משתמש ב-COMFYUI כמנוע היצירה WatchTower - דוקר קטן שמעדכן אוטומטית את כל הדוקרים שמותקנים לגרסה האחרונה Whisper WebUI - אפליקציה להמרה מדיבור לטקסט. משמשת בעיקר לחילוץ כתוביות לסרטים וסדרות. מאפשרת גם תרגום. Zonos - כלי AI לייצור קול מטקסט, עם יכולת חיקוי קולות (VOICE CLONING) במגוון שפות, ומתן גוון רגשי Zonos Hebrew - כלי AI לייצור קול מטקסט, עם יכולת חיקוי קולות (VOICE CLONING) בעברית בלבד (הממשק באנגלית) Kavita - שרת לאירוח קבצי ספרים אלקטרוניים (e-books), אותם אפשר לקרוא מכל מקום, באפליקציה או בדפדפן. Komga - שרת לאירוח קבצי ספרים אלקטרוניים (e-books), אותם אפשר לקרוא מכל מקום, באפליקציה או בדפדפן. AudioBookShelf - שרת לאירוח קבצי ספרים קוליים (audiobooks) להם אפשר להקשיב מכל מקום, באפליקציה או בדפדפן. WPS Office - דוקר של אפליקציות דמויות אופיס (וורד, אקסל, פאוורפוינט וכדומה) LibreOffice - דוקר של אפליקציות אופיס עם אפשרות לתוספים רבים, ביניהם חיבור ל-OLLAMA לעריכה ותוספת טקסט באמצעות בינה מלאכותית Portainer - זו פלטפורמה לניהול דוקרים וקונטיינרים. היות והיא יושבת על בסיס של אפליקציית דוקר קיימת, היא רצה בעצמה על דוקר. מקלה על ניהול הדוקרים ושינוי פרמטרים שלא דרך שורת פקודה (טרמינל). ViniPlay - מיועדת לניגון IPTV. ספציפית רשימות M3U או לינקים ישירים בפורמט TS. לא מכילה רשימות (צריך למצוא לבד). Changedetection.io - לבדיקת שינויים באתרים ברשת - בדומה למה שעושה האתר VISUALPING. docker-cron-restart-notifier - מטרתו לאתחל דוקרים בזמנים מוגדרים מראש. NETALERTX - מנטר את חיבורי הרשת בתוך הרשת הביתית שלי (כך אפשר לראות אם מתחברים משתמשים לא מורשים, למשל). 09/12/2025: הוספתי דוקר של CREWAI STUDIO (לבניית סוכני AI), והסרתי את NETALERTX מפני שהוא הפסיק לפעול כמו שצריך לאחר העדכון האחרון (לא מצליח לאתר מכשירים על הרשת מעבר ל-NAS ונקודת הכניסה לנתב). זו הרשימה הנוכחית: Coturn - שרת סיגנלים שמיועד להכוונת וידאו בפורמט WEBRTC (בלעדיו אי אפשר להריץ ווידאו קונפרנס כמו שצריך) Stable Diffusion Forge - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה G4F - ממשק המתחבר לשירותי בינה מלאכותית לצ'אט ויצירת תמונה ברשת ומרכז את כולם במקום אחד HomeAssistant - אפליקציה לניהול בית חכם InvokeAI - בינה מלאכותית לייצור תמונות מטקסט. מתעדכנת וקלה יותר לשימוש Jackett - דוקר לחיפוש טורנטים במגוון מנועי חיפוש. מיועד בעיקר לחיפוש אוטומטי של סדרות וסרטים בשילוב עם Sickchill (למשל) Krita - עורך תמונות בדומה לפוטושופ. קיימת גם עבור חלונות. יש לשים לב שכדי להריץ את פונקציות ה-AI של האפליקציה (בדומה ל-FIREFLY של ADOBE), צריך להתקין את תוסף ה-AI, וגם דוקר מתאים (COMFYUI) MKVToolNix - כלי שמאפשר עריכת קבצי MKV בלי קידוד מחדש. אפשר להוסיף ולהסיר פסי קול, פסי וידאו, וכתוביות. ComfyUI-Nvidia - דוקר להרצת יצירת תמונות ווידאו ב-AI בעזרת כרטיס גרפי Mirotalk P2P - שיחות וידאו אודיו וצ'אט. מתוחכם ועובד מכל דפדפן. כולל כמובן טלפונים ניידים. Navidrome - ניהול אוסף מוסיקה, כולל עדכון אוטומטי של תמונות אלבום, מידע, וכמובן נגן מובנה ותמיכה באפליקציה לטלפון. Ollama + OpenWebUI - אפליקציה מובילה לצ'אט בינה מלאכותית מקומי. משתמש בכרטיס מסך אם כי יכול לעבוד גם עם מעבד בלבד. Text-Generation-WebUI - אפליקציה נוספת לשימוש עם מודלים לצ'אט בינה מלאכותית מקומי. יותר מסובך לעבוד איתו, אבל יותר מהיר ומאפשר חיפוש רשת קל יותר. Stable Diffusion reForge - עוד בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה. SD.Next - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה SearXNG - מנוע חיפוש מקומי שמשלב חיפוש במספר מנועים גלובליים (משמש גם עבור OLLAMA לחיפוש רשת) SwarmUI - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה - משתמש ב-COMFYUI כמנוע היצירה WatchTower - דוקר קטן שמעדכן אוטומטית את כל הדוקרים שמותקנים לגרסה האחרונה Whisper WebUI - אפליקציה להמרה מדיבור לטקסט. משמשת בעיקר לחילוץ כתוביות לסרטים וסדרות. מאפשרת גם תרגום. Zonos - כלי AI לייצור קול מטקסט, עם יכולת חיקוי קולות (VOICE CLONING) במגוון שפות, ומתן גוון רגשי Zonos Hebrew - כלי AI לייצור קול מטקסט, עם יכולת חיקוי קולות (VOICE CLONING) בעברית בלבד (הממשק באנגלית) Kavita - שרת לאירוח קבצי ספרים אלקטרוניים (e-books), אותם אפשר לקרוא מכל מקום, באפליקציה או בדפדפן. Komga - שרת לאירוח קבצי ספרים אלקטרוניים (e-books), אותם אפשר לקרוא מכל מקום, באפליקציה או בדפדפן. AudioBookShelf - שרת לאירוח קבצי ספרים קוליים (audiobooks) להם אפשר להקשיב מכל מקום, באפליקציה או בדפדפן. WPS Office - דוקר של אפליקציות דמויות אופיס (וורד, אקסל, פאוורפוינט וכדומה) LibreOffice - דוקר של אפליקציות אופיס עם אפשרות לתוספים רבים, ביניהם חיבור ל-OLLAMA לעריכה ותוספת טקסט באמצעות בינה מלאכותית Portainer - זו פלטפורמה לניהול דוקרים וקונטיינרים. היות והיא יושבת על בסיס של אפליקציית דוקר קיימת, היא רצה בעצמה על דוקר. מקלה על ניהול הדוקרים ושינוי פרמטרים שלא דרך שורת פקודה (טרמינל). ViniPlay - מיועדת לניגון IPTV. ספציפית רשימות M3U או לינקים ישירים בפורמט TS. לא מכילה רשימות (צריך למצוא לבד). Changedetection.io - לבדיקת שינויים באתרים ברשת - בדומה למה שעושה האתר VISUALPING. docker-cron-restart-notifier - מטרתו לאתחל דוקרים בזמנים מוגדרים מראש. NETALERTX - מנטר את חיבורי הרשת בתוך הרשת הביתית שלי (כך אפשר לראות אם מתחברים משתמשים לא מורשים, למשל). CrewAI Studio - דוקר ליצירת סוכני AI למשימות מוגדרות (לדוגמא: איסוף מידע על נושא ויצירת סיכום, ואז עם סוכן שני, הצגת הסיכום במספר סעיפים קטן) 10/12/2025: עדכנתי את המטען של תוכנת ARC LOADER עבור XPENOLOGY לגרסה האחרונה (3.0.7), לשיפור היציבות והביצועים. זה עבר חלק יותר מאשר שחשבתי, גם אם נאלצתי לרשום ARC PATCH מחדש ולבנות את המטען מחדש כדי לאפשר את השירותים המקוונים של SYNOLOGY (עבור גיבויים מרוחקים למשל) 12/01/2026: מסתבר שלהשתמש ב-REVERSE PROXY זה פחות מאובטח ויותר בעייתי כשמאפשרים גישה מבחוץ. אז מה שעשיתי זה להוסיף דוקר בשם NGINX PROXY MANAGER שלוקח על עצמו את כל הגישה מבחוץ ומפנה אל שרתי הדוקר בפורטים המתאימים תוך שימוש בDYNAMIC DNS וגם סרטיפקטים מתאימים בפורמט SSL. מה שזה אומר זה שפותחים הרבה פחות פורטים בנתב, ואז הגישה לשרת שלך יותר מאובטחת ופחות מחוררת. השתמשתי במדריך הזה, אבל עם שינויים מסוימים בשביל שיעבוד דרך PORTAINER: https://mariushosting.com/how-to-install-nginx-proxy-manager-on-your-synology-nas/ רשימת הדוקרים הנוכחית: Coturn - שרת סיגנלים שמיועד להכוונת וידאו בפורמט WEBRTC (בלעדיו אי אפשר להריץ ווידאו קונפרנס כמו שצריך) Stable Diffusion Forge - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה HomeAssistant - אפליקציה לניהול בית חכם InvokeAI - בינה מלאכותית לייצור תמונות מטקסט. מתעדכנת וקלה יותר לשימוש Jackett - דוקר לחיפוש טורנטים במגוון מנועי חיפוש. מיועד בעיקר לחיפוש אוטומטי של סדרות וסרטים בשילוב עם Sickchill (למשל) SichChill - דוקר לארגון סדרות עם שילוב של חיפוש ואפשרות הורדה אוטומטית של פרקים חדשים Krita - עורך תמונות בדומה לפוטושופ. קיימת גם עבור חלונות. יש לשים לב שכדי להריץ את פונקציות ה-AI של האפליקציה (בדומה ל-FIREFLY של ADOBE), צריך להתקין את תוסף ה-AI, וגם דוקר מתאים (COMFYUI) MKVToolNix - כלי שמאפשר עריכת קבצי MKV בלי קידוד מחדש. אפשר להוסיף ולהסיר פסי קול, פסי וידאו, וכתוביות. ComfyUI-Nvidia - דוקר להרצת יצירת תמונות ווידאו ב-AI בעזרת כרטיס גרפי Mirotalk P2P - שיחות וידאו אודיו וצ'אט. מתוחכם ועובד מכל דפדפן. כולל כמובן טלפונים ניידים. Navidrome - ניהול אוסף מוסיקה, כולל עדכון אוטומטי של תמונות אלבום, מידע, וכמובן נגן מובנה ותמיכה באפליקציה לטלפון. Ollama + OpenWebUI - אפליקציה מובילה לצ'אט בינה מלאכותית מקומי. משתמש בכרטיס מסך אם כי יכול לעבוד גם עם מעבד בלבד. Text-Generation-WebUI - אפליקציה נוספת לשימוש עם מודלים לצ'אט בינה מלאכותית מקומי. יותר מסובך לעבוד איתו, אבל יותר מהיר ומאפשר חיפוש רשת קל יותר. SD.Next - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה SearXNG - מנוע חיפוש מקומי שמשלב חיפוש במספר מנועים גלובליים (משמש גם עבור OLLAMA לחיפוש רשת) SwarmUI - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה - משתמש ב-COMFYUI כמנוע היצירה WatchTower - דוקר קטן שמעדכן אוטומטית את כל הדוקרים שמותקנים לגרסה האחרונה Whisper WebUI - אפליקציה להמרה מדיבור לטקסט. משמשת בעיקר לחילוץ כתוביות לסרטים וסדרות. מאפשרת גם תרגום. Zonos - כלי AI לייצור קול מטקסט, עם יכולת חיקוי קולות (VOICE CLONING) במגוון שפות, ומתן גוון רגשי Zonos Hebrew - כלי AI לייצור קול מטקסט, עם יכולת חיקוי קולות (VOICE CLONING) בעברית בלבד (הממשק באנגלית) Komga - שרת לאירוח קבצי ספרים אלקטרוניים (e-books), אותם אפשר לקרוא מכל מקום, באפליקציה או בדפדפן. AudioBookShelf - שרת לאירוח קבצי ספרים קוליים (audiobooks) להם אפשר להקשיב מכל מקום, באפליקציה או בדפדפן. LibreOffice - דוקר של אפליקציות אופיס עם אפשרות לתוספים רבים, ביניהם חיבור ל-OLLAMA לעריכה ותוספת טקסט באמצעות בינה מלאכותית Portainer - זו פלטפורמה לניהול דוקרים וקונטיינרים. היות והיא יושבת על בסיס של אפליקציית דוקר קיימת, היא רצה בעצמה על דוקר. מקלה על ניהול הדוקרים ושינוי פרמטרים שלא דרך שורת פקודה (טרמינל). ViniPlay - מיועדת לניגון IPTV. ספציפית רשימות M3U או לינקים ישירים בפורמט TS. לא מכילה רשימות (צריך למצוא לבד). Changedetection.io - לבדיקת שינויים באתרים ברשת - בדומה למה שעושה האתר VISUALPING. docker-cron-restart-notifier - מטרתו לאתחל דוקרים בזמנים מוגדרים מראש. Nginx Proxy Manager - דוקר שמטרתו לאחד את כל ההפניות לשרתים שיושבים במקום אחד עם פורטים פנימיים באמצעות שימוש ב-DDNS וסרטיפיקט SSL בצורה מאובטחת. 23/02/2026: הסרתי והוספתי כמה דוקרים, בינהם דוקר מאוד שימושי (DOCKWATCH) שמאפשר עדכון וניטור של כל הדוקרים הקיימים (ואז אפשר לראות אם אחד או יותר מהם עושה שימוש מוגזם במעבד או בזכרון - מה שמעלה את צריכת המתח של השרת), וגם את RUSTDESK שמאפשר התחברות מרחוק למחשבים וטלפונים - רק שהתעבורה תעבור דרך השרת שלכם ולא שרת אחר ברשת רשימת הדוקרים הפעילים הנוכחית: AudioBookShelf - שרת לאירוח קבצי ספרים קוליים (audiobooks) להם אפשר להקשיב מכל מקום, באפליקציה או בדפדפן Changedetection.io - לבדיקת שינויים באתרים ברשת - בדומה למה שעושה האתר VISUALPING ComfyUI-Nvidia - דוקר להרצת יצירת תמונות ווידאו ב-AI בעזרת כרטיס גרפי Coturn - שרת סיגנלים שמיועד להכוונת וידאו בפורמט WEBRTC (בלעדיו אי אפשר להריץ ווידאו קונפרנס כמו שצריך) docker-cron-restart-notifier - מטרתו לאתחל דוקרים בזמנים מוגדרים מראש DockWatch - ניטור ועדכון אוטומטי של הדוקרים שרצים HomeAssistant - אפליקציה לניהול בית חכם Jackett - דוקר לחיפוש טורנטים במגוון מנועי חיפוש. מיועד בעיקר לחיפוש אוטומטי של סדרות וסרטים בשילוב עם Sickchill (למשל) KMS - שרת ניהול רשיונות מיקרוסופט Komga - שרת לאירוח קבצי ספרים אלקטרוניים (e-books), אותם אפשר לקרוא מכל מקום, באפליקציה או בדפדפן Krita - עורך תמונות בדומה לפוטושופ. קיימת גם עבור חלונות. יש לשים לב שכדי להריץ את פונקציות ה-AI של האפליקציה (בדומה ל-FIREFLY של ADOBE), צריך להתקין את תוסף ה-AI, וגם דוקר מתאים (COMFYUI) LibreOffice - דוקר של אפליקציות אופיס עם אפשרות לתוספים רבים, ביניהם חיבור ל-OLLAMA לעריכה ותוספת טקסט באמצעות בינה מלאכותית Mirotalk P2P - שיחות וידאו אודיו וצ'אט. מתוחכם ועובד מכל דפדפן. כולל כמובן טלפונים ניידים MKVToolNix - כלי שמאפשר עריכת קבצי MKV בלי קידוד מחדש. אפשר להוסיף ולהסיר פסי קול, פסי וידאו, וכתוביות Navidrome - ניהול אוסף מוסיקה, כולל עדכון אוטומטי של תמונות אלבום, מידע, וכמובן נגן מובנה ותמיכה באפליקציה לטלפון Nginx Proxy Manager - דוקר שמטרתו לאחד את כל ההפניות לשרתים שיושבים במקום אחד עם פורטים פנימיים באמצעות שימוש ב-DDNS וסרטיפיקט SSL בצורה מאובטחת Ollama + OpenWebUI - אפליקציה מובילה לצ'אט בינה מלאכותית מקומי. משתמש בכרטיס מסך אם כי יכול לעבוד גם עם מעבד בלבד OnlyOffice - אוסף תוכנות אופיס עם תמיכה בפורמטים של מיקרוסופט RustDesk - שרת לשליטה מרחוק (במקום שירותים כמו ANYDESK שמנווטים את התקשורת שלכם דרך שרתים שלהם, תעברו דרך השרת שלכם) SearXNG - מנוע חיפוש מקומי שמשלב חיפוש במספר מנועים גלובליים (משמש גם עבור OLLAMA לחיפוש רשת) ViniPlay - מיועדת לניגון IPTV. ספציפית רשימות M3U או לינקים ישירים בפורמט TS. לא מכילה רשימות (צריך למצוא לבד) Portainer - זו פלטפורמה לניהול דוקרים וקונטיינרים. היות והיא יושבת על בסיס של אפליקציית דוקר קיימת, היא רצה בעצמה על דוקר. מקלה על ניהול הדוקרים ושינוי פרמטרים שלא דרך שורת פקודה (טרמינל) Stable Diffusion Forge - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה InvokeAI - בינה מלאכותית לייצור תמונות מטקסט. מתעדכנת וקלה יותר לשימוש SichChill - דוקר לארגון סדרות עם שילוב של חיפוש ואפשרות הורדה אוטומטית של פרקים חדשים Text-Generation-WebUI - אפליקציה נוספת לשימוש עם מודלים לצ'אט בינה מלאכותית מקומי. יותר מסובך לעבוד איתו, אבל יותר מהיר ומאפשר חיפוש רשת קל יותר SD.Next - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה SwarmUI - בינה מלאכותית לייצור תמונות ווידאו מטקסט, או תמונה - משתמש ב-COMFYUI כמנוע היצירה WatchTower - דוקר קטן שמעדכן אוטומטית את כל הדוקרים שמותקנים לגרסה האחרונה Whisper WebUI - אפליקציה להמרה מדיבור לטקסט. משמשת בעיקר לחילוץ כתוביות לסרטים וסדרות. מאפשרת גם תרגום. Zonos - כלי AI לייצור קול מטקסט, עם יכולת חיקוי קולות (VOICE CLONING) במגוון שפות, ומתן גוון רגשי Zonos Hebrew - כלי AI לייצור קול מטקסט, עם יכולת חיקוי קולות (VOICE CLONING) בעברית בלבד (הממשק באנגלית) 02/04/2026: שינויים בחיבור האינטרנט שלי (מ-1G קפיצה עצומה ל-10G) דרשו ממני תוספות ושינויים לתשתית האינטרנט הביתית שלי. החל מהחלפת נתב לאחד שתומך בחיבור במהירות 10G, דרך תוספת מתג (SWITCH) 10G עם מחברי SFP+ מתאימים, וכרטיסי רשת שיכולים לנצל את המהירות שעבורה אני משלם (10G). לאחר הרבה עבודה ושינויים, הצלחתי לחבר את המתאם USB-LAN 5G שחיברתי לשרת (רק לאחר רכישת מפצל USB עם מתח - כי ללוח מסתבר שאין מספיק כוח להזין למתאם כך שיעבוד), למתג ודרכו לנתב ולרשת. ועכשיו אני יכול לנצל את המהירות המלאה במחשב האישי, וחצי ממנה (5G) בשרת ה-NAS שלי. זו המהירות שאני מודד מהאינטרנט (דרך דפדפן פיירפוקס שהתקנתי על ה-NAS): 25/07/2026: אין שינויים משמעותיים. עברתי להשתמש בעיקר ב-DOCKHAND במקום PORTAINER כי הוא עושה אוטומציה לעדכון הדוקרים, וקל יותר לשימוש בכל מיני מובנים. התחלתי לשחק עם סוכני AI על השרת (הרמס), זה עבד בסדר בהתחלה ואז נשבר כתוצאה משינויים שעשיתי. אבל הבעיה המשמעותית היא האיזון בין גודל המודל לגודל הקונטקסט. הקונטקסט נגמר מהר ואז המודל נחנק או שוכח את מה שעבד עליו. יש לזה פתרונות אבל זה די מתסכל. הוספתי עוד כמה דוקרים והורדתי אחרים. בתחום המוסיקה לא הצלחתי למצוא בינתיים אחד שעובד בצורה טובה מבחינת חיפוש ורשימות השמעה - כמו דיזר או ספוטיפיי. אמשיך לחפש..













.thumb.png.aa61af91048fc595917454e36b0a6c9c.png)




 1 point
1 point -
1 pointאז לך על לנובו / אסוס עם מעבד שהציע ג'אברווק, או שאפשר להסתפק בלנובו שבחרת.1 point
-
1 pointטוב חטאתי ופשעתי וגם אני נעזרתי ב - A.I לראות מי נגד מי. אז אני לא אהיה המלפפון שיכה את הגנן, אבל ... בוא, אתה לבד יודע מה צריך ולמה. יש כמובן בעיה "קטנה" - תקציב. אז אחסוך לך בנושא הזה את ההתלבטות. אין קיצורי דרך. בטח לא היום = בזמן הנוכחי והקרוב. זו תקופה מחורבנת בלשון המעטה לקניית מחשב באשר הוא. איך אומרים ? הטיימינג הוא הכל בחיים ... נייד מתאים יעלה לך כפליים וצפונה ...1 point
-
1 pointהיי ה - AI לא ממש תחום שלי, אבל ... הייתי מחפש נייד עם מעבד אינטל מהדור האחרון או, לחילופין מחפש נייד עם מעבד AMD כמו בנייד של לנובו ( השני ) בגלל ביצועי AI עדיפים בהרבה מהמעבד שבנייד הראשון. כל זה נכון אם כרטיס מסך לא כזה משנה במה שאתה עושה, וכאמור אני לא בקי בתחום. כלומר, אתה צריך לראות מה יותר חשוב, כרטיס מסך נפרד או מעבד .1 point
-
במחשבה שניה ושלישית .... ככה ראשית, אינטל מחליפה אוטוטו את התושבת הנוכחית ( 1851 ) , מקווה מאוד לא ל - 1852 ... כך שאם אפשר, אולי כדאי להמתין עם כל המהלך של רכישת מחשב חדש. לגופו של המעבד - הוא די תפור לצרכים שלך. בימינו, כל מחשב עריכה / תלת מחייב קירור נוזלי, בוא נאמר מאז מעבד בסדר גודל של 13900 ... נכון שמעבדי AMD קרירים יותר, אבל להם יש גיבנות אחרות. רק לסבר את האוזן, ה - Core Ultra 7 270K Plus טוב לליטרום אבל לא משהו לפוטושופ. הוא כן מצויין לווידיאו, בגלל זה אמרתי שהוא בול עבורך. כשמשדכים ל - Core Ultra 7 270K Plus זיכרון מהיר מקבלים באמת ביצועי סופר. אבל שוב, השאלה אם להשקיע עכשיו במשהו שעוד מעט יהיה שייך לעבר ( מבחינת התושבת ).1 point
-
הוא לא פחות חזק , למעשה הוא טיפה יותר חזק אבל הוא צורך יותר חשמל . אז אתה מקבל שיפור של 5% בביצועים ( עם חסכון במחיר ) אבל צריכת חשמל של המעבד עולה משיא של 185 וואט לשיא של 240 וואט. זה גם אומר שצריך לתת דגש יותר מהותי לקירור . עד 200 וואט יש המון אופציות שעושות את העבודה וזה רק עניין של שקט יותר או פחות ביחס למחיר. 240 וואט כבר מחייב אותך ללכת על הפרימיום של קירורי האוויר או קירור מים טוב.1 point
-
זה קורה לכולן, פחות או יותר. אבל אפל לרוב מצליחה להשכיח את הכשלונות שלה, ומציגה מצג של מושלמות ללא עוררין. ynet50 שנה לאפל: הכישלונות המפוארים שהיא הייתה מעדיפה שתשכחומאחורי ההצלחה האדירה של האייפון והמקבוק מסתתרת רשימה ארוכה של הימורים שלא עבדו. מפרויקטים שעלו מיליארדים ונקברו, ועד מוצרים יומרניים שהגיעו לשוק והפכו לבדיחה. חזרנו לכמה מהפספוסים הגדולים שאפל הייתה מ חג שמח !1 point
-
הנה עוד סרטון שבו הניאו מוצג באור חיובי https://www.youtube.com/watch?v=LSKhJJtfuqQ חיובי לכאורה ... אין תאורה במקלדת, הרמקולים בכלל לא משהו וכו' וכו'. בקיצור, הכלה קצת בהריון,אבל חוץ מזה - נהדרת ...1 point
-
לא יודע מאיפה הביטחון מה ראיתי ומה לא. לעצםהעניין - זמן סוללה רחוק כמו מכאן עד טהראן לעומת מה שאפל מפרסמים. אותו דבר ניתן לומר ביחס לכל תכונה שאפל טוענת. וכל האותות והמופתים שכתבת, לא יסתירו עובדה פשוטה אחת - יש חלופות יותר טובות במיר של הניאו.1 point
-
1 pointהיי, לפי מה שאתה מתאר – זה בדיוק מקרה קלאסי של מעבר מכלי "נוח ומהיר" (כמו Google Apps Script) למשהו שבאמת בנוי למערכת דינמית. Apps Script אחלה לדברים קטנים/אוטומציות, אבל ברגע שאתה צריך: - ניהול דפים - CRUD (יצירה/עריכה/מחיקה) - עבודה מסודרת מול DB - ושליטה מלאה בלוגיקה כבר עדיף לעבור לאחסון רגיל. מה שאתה מחפש זה לא "אתר מוכן", אלא שרת (אחסון) שמריץ קוד — לרוב PHP/Node + מסד נתונים (MySQL למשל). זה כן נכנס תחת "אחסון אתרים", פשוט מהסוג הדינמי. אני עברתי תהליך מאוד דומה כשבניתי מערכת ניהול תורים, ובהתחלה גם ניסיתי פתרונות פחות גמישים. ברגע שעברתי ל־PHP + MySQL על אחסון רגיל, הכל נהיה הרבה יותר פשוט ויציב. מבחינת התחלה: - אחסון Linux בסיסי - PHP - MySQL זה מספיק ל־90% מהפרויקטים מהסוג הזה. אם תרצה בעתיד – תמיד אפשר לשדרג לשרת חזק יותר או לעבור לארכיטקטורה מורכבת יותר .1 point
-
הנה משהו יותר מפורט ומפורק ובנימה רצינית יותר על הנייד הנ"ל ... ביקורת עניינית ולא כל מיני דיקלומים של מחלקת השיווק של אפל. https://www.youtube.com/watch?v=Ga9NAZLCQpc1 point
-
שלום לכולם ! הכצעקתה ? נו, קשה לדעת. תראו את זה כאן ( דקה 4 בסרטון ) - https://www.youtube.com/watch?v=y5WM9XC_2ho לו יהי ...1 point
-
בלי אירועים נוצצים, יוצרת ChatGPT שחררה מתחרה ישיר לגוגל טרנסלייט. הוא נראה כמעט אותו דבר, אבל מציע יכולת עריכה שגוגל פשוט לא נותנת - וזה הופך את החיים להרבה יותר קליםלכתבה1 point
-
אם אתם מעל גיל 18 ויש לכם מקום עבודה 5 דק' מזמנכם יעזרו לי נורא הלינק לשאלון: https://forms.gle/iCkm6cQU51d7x6kJ6 חברים ומשפחה יקרים, אחרי תקופה ארוכה של לילות לבנים, חישובים ונתונים, אני סוף סוף נמצא בשלב המכריע של עבודת התזה שלי בתואר שני בסטטיסטיקה. אני חוקר נושאים שבוערים היום בשוק העבודה: בריונות במקום העבודה ו"התפטרות שקטה" (Quiet Quitting). כדי להפוך את המחקר הזה למשמעותי, אני זקוק לעזרתכם באיסוף נתונים. מבטיח שזה קצר: זה לוקח בדיוק 5 דקות. השאלון הוא אנונימי לחלוטין. כל מענה מקדם אותי צעד ענק לסיום התואר. אשמח מאוד אם תוכלו להקדיש כמה דקות ולענות, ואפילו לשתף את הפוסט כדי שאוכל להגיע לכמה שיותר אנשים. הלינק לשאלון https://forms.gle/iCkm6cQU51d7x6kJ6 תודה ענקית לכל מי שיכול לעזור 3>!
 1 point
1 point -
1 pointלהשאיר תמיד דלוק. גם נתב (ראוטר) וגם מפסק (סוויץ'). גם אין צורך לכבות, וגם זה רק ייצור בעיות אם תכבה ותדליק.1 point
-
1 pointתזיז את התחת אם יש מוצר אישי, זה בטח מזרן. כלומר, מה שמתאים לי, יכול להיות סיוט בשבילך ולהפך. לכן, אם באמת חשקה נפשך במשהו טוב ואיכותי, כתת רגלייך לחנות מתאימה ובלי היסוס ( החנויות הרציניות אפילו ממליצות על סף מחייבות התנסות מעשית ) תשכב ותרגיש סוגים שונים של מזרנים. מה שירגיש לך טוב ונוח, תקנה.1 point
-
https://www.plonter.com/products_results.tmpl?command=search&db=^catalog.txt&eqcategorydatarq=%E7%EC%F7%E9%20%EE%E7%F9%E1&eqdivisiondatarq=%E3%E9%F1%F7%E9%ED%20%F7%F9%E9%E7%E9%ED%20%E5%20SSD&eqshelfdatarq=SSD%20-%20SATA&cart=176846452368252288&lang=heb&price_totalTYPE=num&price_totalsort=1&show=1 מחירי הSSD כאן נראים יותר טובים לא יודע אם הם מוכרים אותם ללא מחשב מסביב.1 point
-
במסגרת תערוכת CES 2026 הודיעה היום חברת SanDisk על השקת SANDISK Optimus כשם החדש לליין כונני ה-SSD הפנימיים המובילים שלה לגיימרים, יוצרים ואנשי מקצוע. זה הוא מיתוג מחדש לכונני WD הקיימיםלכתבה1 point
-
במשך כמעט שני עשורים, כתובת ה-Gmail שלנו הייתה מעין "חתונה קתולית" דיגיטלית - ברגע שבחרתם אותה, נתקעתם איתה לנצח. כעת, מסמך תמיכה רשמי חושף כי גוגל נערכת לשינוי דרמטי במדיניות הנוקשה ביותר שלה, שיאפשר למשתמשים להיפרד מכינויים מביכים מהעבר מבלי לוותר על היסטוריית המיילים או הקבצים שלהםלכתבה1 point
-
1 pointההבדל במעבדים זניח במציאות לדעתי הזיכרון היותר גדול יותר משמעותי אבל אם אתה מחפש לגיימנג אז העדיפות היא לכרטיס מסך יותר חזק אפילו עם מעבד יותר חלש אבל האופציות בניידים די מוגבלות, תבדוק אם 5070 יכנס לך לתקציב הערת צד אם המחשב יהיה במקום כל הזמן אז למה לא שולחני, תקבל חומרה הרבה יותר חזקה ומסך יותר גדול באותו המחיר כרטיס מסך 5060 נייד זה לו אותו אחד כמו בנייח , הנייח ב 20% יותר מהיר אם לא יותר, כנל למעבדים1 point
-
בטוח יעזור יותר וואטג' = מהירות חישוב. אבל אם הייתי צריך לבחור בין זה לVRAM הייתי בוחר בVRAM בלי לחשוב פעמיים.1 point
-
בדיוק היום לפני 35 שנה, שוחרר המשחק הצנוע שהוכיח שה-PC יכול להתחרות בקונסולות. הכותר הזה לא רק הציג פריצת דרך טכנולוגית בלתי נתפסת לאותה תקופה, אלא גם סלל את הדרך להקמתה של האימפריה שתמציא מאוחר יותר את ז'אנר היריות בגוף ראשון. כך הפכה דחייה מנינטנדו לרגע המכונן של הגיימינג המודרנילכתבה1 point
-
10.12.2025 רכשתי בארץ 3 SSD מיקרון 5400 בחיבור SATA בנפח TB 1.92 כל אחד, מדובר בדיסקים אינטפרייז שפורקו מSTORAGE , מצב חיים 96% . 14 אלף שעות עבודה. עלות 500 ₪ הייתה לי התלבטות האם לרכוש TB 7.68 גם סמסונג PM883 אינטרפייז ב700 ₪ אך עם WEAR LEVEL 83% , זה לא רע, אבל כבר הפוך את העסק ליקר. מטרת הרכישה היא ליצור RAIDZ1 עליו אאחסן את הקבצים של IMMICH & NEXTCLOUD על מנת שדיסקים קשיחים לא יתעוררו בכל פעם שפונים לשירות. הזמנתי בקר לשישה חיבורי SATA מ NVME. עלות $14 הבקר יחליף את הכונן הNVME הקטן 256GB שאין לו בו שימוש מהותי. אגב בחיפוש באלי אקספרס נתקלתי במארז JONSBO N4 במחיר 418 ₪ ($129) בשימוש בקופון. המארז מתאים ללוח M-ATX ויש לו מקום ל6 דיסקים 3.5 ועוד 2 כוננים 2.5. *לא יודע לגבי תשלום מע"מ אבל אם נדרש הוא 95 ש"ח. כנראה שבעתיד הרחוק אשדרג את המארז עקב חוסר מקום אולי ל JONSBO N6 החדש.
 1 point
1 point -
המחשב השני . כי יתן תפוקה טובה יותר. נכון שההדמיות נסמכות על כרטיס מסך, אבל עדיין, מעבדי אולטרה הם נפילה גדולה. לא הייתי נותן משקל גדול מידי לענין האחריות לשני המקומות.1 point
-
1 pointזה ספק כוח זול ולא איכותי , אני לא יכול להמליץ עליו . אם המחשב חשוב לך ואתה רוצה למזער את הסיכוי לנזקים ללוח האם ושאר החלקים של המחשב , עדיף את ה ELITE NEX PN 600W. זה לא קשור לשאלה אם זה 500 וואט או 600 וואט , זה קשור לאיכות של רכיבי ההגנה שקיימים בספק .1 point
-
1 pointיש משחקים שבהם זה יכול לסייע , כל מה שחדש ומוגדר "כבד" . ראה system requirements . אם אתה רוכש 2 נוספים של 16 , תוודא שאתה רוכש בדיוק אותו הדבר. שים לב שמשפחת ה 5000 אפילו מעדיפה 4 rank , כאשר 2 של 8 הם די בוודאות 2 RANK . 2 של 16 לרוב יהיו 4 rank אבל צריך לוודא. אז בעקרון 4 של 8 עשוי גם לתת שיפור ביצועים קל בלי קשר לצריכת זכרון , עשו בזמנו מבחנים , צריך לחפש.1 point
-
https://www.google.com/search?q=Houdini+-+MAC+OR+PC&sa=N&sca_esv=3a311592578585b5&udm=50&fbs=AIIjpHxU7SXXniUZfeShr2fp4giZjSkgYzz5-5RrRWAIniWd7tzPwkE1KJWcRvaH01D-XIWOFp4UhuzIxwLSKiE1xF1ZWEqjZkRe51b9jK6AN71wXGlgfMAjhu_nxvE2OTRS_qJ8TIbYtQEGwTAxcUtLYkJKqs6wYgm-h8dEhSDi7piZRVgyJZhh8u7ig2JpG9aWk9w-wgD1_NBTB6UetozDfKxaC98Rbg&aep=1&ntc=1&ved=2ahUKEwirq_OthveQAxWz9rsIHdBYBd44FBDYnw56BAgMEAQ&biw=2327&bih=1163&dpr=1.1&mstk=AUtExfC2nTQDLRnaHx9kA1bXb9C8KaL92_QzY9yWwC6u7nMnj-GYSHuetyI3IK7bF5wWkFGGkiuaeodTm2EB3Tb_TNtp8FIROfjxPYZ6jqN1H76Wd3lHEV1hLtRoJiR5yhp61TL3trtOKmHj-Y6LTIcHaQBspn1JSvxgdq0&csuir=1 https://www.reddit.com/r/Houdini/comments/1hvonat/mac_for_houdini_and_unreal_engine/#:~:text=I've%20run%20Houdini%20on,a%20Windows%20desktop%20running%20Houdini .https://www.youtube.com/watch?v=6QpUkqXFcMA בקיצור, נראה לי שהכף נוטה ל - PC. אבל, כדאי לקחת נייד שמאפשר הרבה RAM , יעני אם לא מגיע עם הרבה, שיהיה אפשר לשדרג.1 point
-
1 point
-
יפה יש לו נגן מובנה, זאת אומרת שאני לא צריך להוריד ולהתקין נגן לאנדרואיד. אנסה אותה הסופש. תודה רבה.1 point
-
בקיצור פספסת את ההזדמנות. הדבר היחיד שעוד שווה לעשות זה שהוא יביא לך 5070 , לא משנה איך הוא קונה אותו , אפשר לרכוש באמזון ולשלוח אליו אם זה יכול לקרות מספיק מהר ומסתדר . זה לא יותר מידי טרחה יחסית והחסכון שווה( בערך 1000 ש"ח , חלק זה מעמ וחלק זה בעיית תמחור בארץ ) עדיף 9600X עם 5070 מאשר כל מעבד יותר טוב עם כרטיס פחות טוב .1 point
-
ביחס לזכרון שאתה מציג , לזכרון היקר יש ערך מוסף עצום . פה זה כבר ברמה שכנראה עדיף לקחת את המחשב השני . כל המעבדים כיום ( ולפחות 10 שנים אחורה ) עובדים בערוץ כפול מול הזכרון. זה אומר שכאשר יש בלוח האם 2 יחידות תואמות של זכרון , רוחב הפס של התקשורת בין המעבד לזכרון הוא כפול. 2 סטיקים של זכרון 6400 זה כמו סטיק אחד של 12800 ולצורך העניין 2 סטיקים של 4800 זה כמו אחד של 9600 . סטיק אחד של 5600 זה 5600 והסטיק המדובר הוא עם תזמונים גבוהים ( זה לא טוב. תזמונים נמוכים - זכרון זריז , תזמונים גבוהים - זכרון פחות זריז ) ובנוסף , כפי שהזהרתי לגבי הזכרון הזול הנוסף, סביר מאוד שהמעבד בכלל יגרום לזכרון הזה לעבוד ב 4800 . אז אם למרות הכל מתפשרים על זכרון, אפשר לרכוש 2 סטיקים של זה: https://tms.co.il/samsung-ddr5-16gb-5600mhz-cl46-3rd או 2 סטיקים של זה: https://tms.co.il/hynix-hmcgg6agbub256n הם כנראה יעבדו רק ב 4800 ולא ב 5600, התזמונים כאמור גבוהים מהרצוי , אבל לפחות יהיה לך dual channel והם יעבדו ב 9600 אפקטיבי . סיכוי קטן שהם יעבדו ב 5200 ( רלוונטי גם לזכרון שאתה הצגת ) . נ.ב. 2 זולים של 16 הם יותר זולים מהיחיד של ה 32 ואם מתפשרים על מהירות הזכרון אפשר להתפשר גם על נפח ולקחת 2 של 12 . הלוואי והיה סט של 2X12 במהירות גובה באזור ה 500 ש"ח שהיה נותן פתרון משתלם . מחר אנסה להרכיב לך מפרט בפלונטר למרות שיכול להיות שמה שיחסך בפריט אחד , יגבה מחדש בפריט אחר. כי זה למשל זכרון עם נתונים אידאלים במחיר אידאלי : https://www.plonter.com/detail.tmpl?sku=PVV532G600C30K&lang=heb&cart=1761426327279769511 point
-
כן אפשר להוריד במחיר של המארז אבל יש יותר מידי בשוק ואני לא מכיר כל דבר . פשוט תעביר את המפרט הזה לחנות ותגיד שאתה רוצה מארז יותר זול. הם צריכים לוודא שהוא יכול לקבל את הקירור של המעבד מבחינת גובה. הם צריכים לוודא שהוא יוכל לקבל את כרטיס המסך מבחינת האורך (כרגע זה ממש לא בעיה - אתה יכול לבקש שיהיה מתאים גם לכרטיסים יותר ארוכים ) אתה רוצה שיהיו בו 2 מאווררים אחד מקדימה ואחד מאחורה או 3 מקדימה שזה נפוץ כיום .אני מניח שאפשר גם 2 מקדימה אם המארז קומפקטי למרות שאני הייתי מעביר אחד מהם אחורה . ואם אלו מאווררים עם RGB אז שיהיה ARGB . כשאתה יורד במחיר אתה מוותר על עובי הפח ( רגישות לקרקושים עם הזמן ) , פילטרים לסינון אבק , איכות הרגליות ( גומי או פלסטיק ) ופחות מעניין אותך כי אתה לא מרכיב את המחשב - גימור של שולי המתכת הפנימיים .1 point
-
זוועה, תמתין בבקשה עם הרכישה עד שתקבל פה מענה מאוחר יותר או מחר.1 point
-
לא אמרתי שאין 4K בגודל 24 אינצ'. אמרתי שלא מקובל / רצוי לקנות אחד כזה. אתה צריך לזכור שרזולוציה גדולה במסך קטן ( יחסית ) תראה את האייקונים והכתב בצורה מאוד קטנה. נכון שאפשר לפתור את זה עם הגלת התצוגה, אבל בשביל מה לשלם סתם כסף על תכונה שלא נותנת כלום ?1 point
-
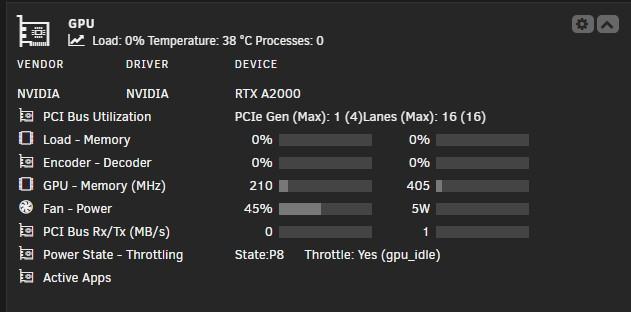
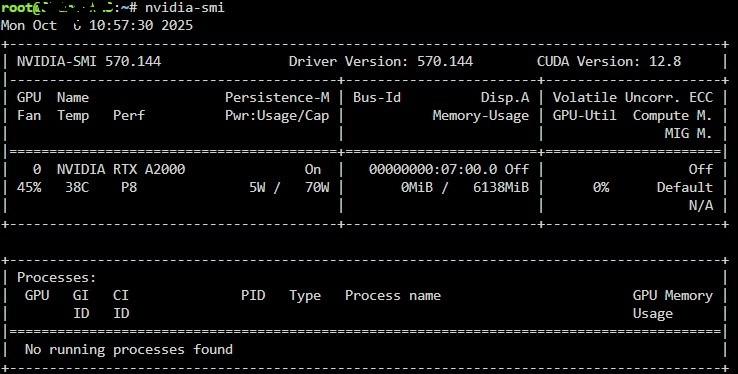
06.10.2025 כמה שידרוגים שעשיתי: תכננתי להוסיף 4 מחברי SATA במקום מתאם JMICRON שכבר יש לי עם 2 חיבורי SATA אני רוצה להוסיף cache pool עם שני כונני SSDבנפח 2-3 טרה של אינטל על מנת ליצור "RAID1" עבור שירותי NEXTCLOUD וIMMICH כדי המערך המכני לא יצטרך להתעורר משינה בכל פעם שמישהו ירצה לפתוח קובץ/תמונה אז קניתי מתאם NGFF עם בקר ASMEDIA עבור ארבע חיבורי SATA לצערי לא הצלחתי לגרום לו לעבוד, כנראה שהגיע תקול, אליאקספרס זיכו אותי. היות והמתאם JMICRON הקיים אפשר לי רק חיבור SATA אחד עקב מגבלת מקום, רכשתי מאריך שאוכל לנצל לפחות את החיבור שהיה חסום פיזית. הכל עבר בשלום, הוספתי SSD 1TBלצורך בדיקה, אך אני עדיין מחפש דרך להוסיף עוד חיבור SATA אחד לפחות מבלי להקריב חיבור M.2 עבור זה. אולי אזמין שוב את הASMEDIA בתקווה שהפעם הוא יעבוד. עלות השידרוג למאריך : $6.25 מאריך למתאם המצב הקודם בחיבורי ה SATA: המצב אחרי : כרטיסי הרחבה 4 פורטים והמאריך : עלות כרטיס ASMEDIA : $17.47 asmedia 4 sata ports רכשתי כרטיס מסך משומש מסוג A2000 6gb , הוא קיים גם בגירסת 12,16 גיגה לשימושי AI עבור ביצועים טובים יותר עבור TRANSCODING ולימוד מכונה, הכרטיס פותח לי דלת לכל מיני פרויקטים שאני שוקל להמשך. (זיהוי פנים/DVR , קצת Aiוכו') העניין עם הכרטיס שרכשתי הוא הגודל הפיזי שלו שתופס 2 חיבור PCI SLOT, ובמארז שלי JONSBO n2 אין פיזית מקום כזה, אז הזמנתי קירור מיוחד שהופך את הכרטיס ל PCI SOLT יחיד, קירור מסיבי וכבד מנחושת. בנוסף הייתי צריך ליצור סקריפט לניהול המאוורר עם מהירות משתנה דינמית כי ברמת ה FRIMWARE של הכרטיס מנסה לעבוד על מינימום והמהירות עולה בצורה לא משביעת רצון, הסקריפט עובד נהדר ומתאים את המהירות בהתאם לטמפ עם מהירות בסיס 45% במקום 30% . בדיקות בעומס הכרטיס מגיע לטמפ של 68-70 מעלות, במקום 89 מעלות עם פרופיל המאוורר המקורי. הכרטיס מבצע הפעולות הרבה יותר מהיר ובקלות ביחס לכרטיס הקודם P400 עלות הכרטיס 600 ₪ עלות הקירור 115 יורו עד לבית (465 ₪) https://n3rdware.com הכרטיס במצבו המקורי: פירוק והחלפה המצב הקודם : טמפ לאחר החלפה:













 1 point
1 point -
1 pointהשירות לא ניתן על ידי היבואן . את השירות אתה בכל מקרה מקבל דרך CPM בלי קשר למקור הרכישה ( אלא אם זה יבואן מקביל ולא רשמי או מחודש וכו' ואז המצב אולי עוד פחות טוב) מבין שלך אישית הייתה חוויה רעה עם DELL אבל ברמת הכלל , מבחינה סטטיסטית , ל DELL יש שירות יותר טוב. מעניין , כמה תלונות חדשות קיימות שם מהשנה האחרונה ? קח בחשבון שבכל שנה בממוצע נמכרים בארץ למעלה מ 750 אלף מחשבים ניידים . ( יש שנות קורונה שנמכרים הרבה יותר ואז אחרי זה נמכרים פחות יש שנות מלחמה שיש עצירה ואז קפיצה ) ואסוס חולשת על בערך 10% מהשוק שזה אומר למעלה מ 75 אלף מחשבים שנמכרים בשנה . זה אומר שבמצב תקין וסביר לפחות 2000 אמורים להיות עם תקלה . כי 97% אחוזי תקינות של מוצר שיוצא מהמפעל זה מצב טוב מאוד , העלייה ל98% תקפיץ לך את המחיר של המוצר בחנות בעשרות אחוזים . עכשיו מתוך ה 2000 האלה , כמה לקחו את הזמן להתלונן בפייסבוק ? האם כל התלונות שלהם נראות לך מוצדקות ב 100% ? מריפרוף אני יכול לראות כמה שבפירוש לא . לפעמים מספרים נותנים תמונה יותר טובה מאשר אנשים מתוסכלים שצועקים חזק ,זה לא אומר שהם בהכרח צודקים .1 point
-
לא . לא אוהב את האתר שלהם. במיקרוסנטר זה איסוף מהחנות או אפילו רכישה בחנות . אני לא יודע אם ניואג זה אותם מחירים , למשל באמזון אין באנדלים כאלה .1 point
-
כן , חד משמעית ה 14700K נותן את התמורה בטובה ביותר . כל החבילה עולה כמו המעבד בלבד בארץ . כל החבילה זה פחות מחצי מחיר מהארץ. לא יאומן , אין מבצעים כאלה בארץ - זה מכירת חיסול! תביא לי גם . נ.ב. כל המחירים הם לפני TAX שבהתאם למדינה שבה אתה תהיה יכול להגיע עד 8% . תבלע את זה , אל תתקמצן . לגבי כרטיס המסך , אם אתה רוצה לחסוך ו550 זה יותר מידי ( ואני ממליץ לא לחסוך ) אז המדרגה הבאה שמשתלם לקחת זה rx 9060 xt-16gb שעולה פחות מ 300$ . ה 5060ti עם 8 גיגה הוא גם נבלה וגם טרפה , ה 5060ti-16gb הזול ביותר שאיכותי עולה בערך 430$ וזה לא בהכרח משתלם ,אולי אם אפשר למוצא בפחות מ 400$ זה רלוונטי . 5060 לא לגעת . כאמור , אם אתה רוצה שקט קדימה ולנצל את ההזדמנות לחסוך הרבה אז 5070 .1 point
-
5070 זה הסעיף הראשון . הוא עולה 550$ . נשאר 450 . באנדלים בחנות כמו מיקרו סנטר זה לדעתי הדבר הנכון . אם הדגש הוא משחקים , אז מעבד 3d : https://www.microcenter.com/product/5007070/amd-ryzen-5-7600x3d,-asus-b650-a-rog-strix-gaming-wifi-am5,-gskill-flare-x5-series-32gb-ddr5-6000-kit,-computer-build-bundle אם אתה רוצה יותר כוח רוחבי אז : https://www.microcenter.com/product/5006970/amd-ryzen-7-9700x,-gigabyte-b650-gaming-x-ax-v2,-gskill-flare-x5-series-32gb-ddr5-6000-kit,-computer-build-bundle אם אתה רוצה אינטל דור קודם אז: https://www.microcenter.com/product/5006974/intel-core-i7-14700k,-asus-z790-gaming-wifi7,-gskill-ripjaws-s5-32gb-kit-ddr5-6000,-computer-build-bundle יש מצב שזה המחשב הכי חזק מבין כולם אבל אתה חייב גם לקנות קירור ( ראה מטה ) ובמקרה של המעבד הזה עדיף את הטוב ביותר . או דור נוכחי אחרון חביב אך הכי חדש , אינטל דור אחרון , קצת חלש במשחקים , יותר יעיל וחזק בשאר הדברים , פחות מתחמם מאינטל דור קודם. https://www.microcenter.com/product/5007077/intel-core-ultra-7-265kf,-asus-z890-ayw-gaming-wifi-w,-gskill-ripjaws-s5-series-32gb-ddr5-6000-kit,-computer-build-bundle בכולם הזכרון הוא cl36 ,עדיף cl30 אבל אלו בנאדלים שחוסכים לך 100$ לפחות ביחס למחיר השוק בארה"ב בעקרון הקירור שלך מספיק טוב, אולי צריך מתאם . תבדוק אם יש לך מתאם ל am5 . יש לי הרגשה שלא . אולי עדיף לרכוש בחול. לחלופין אפשר לרכוש קירור מעולה ב 40$ בערך ( הטווח הוא 35-50 ) בגדול כל הכפולים של thermalright . phantom spirit , peerless assassin ,הכי טוב והכי חדש זה royal pretor 130 , הוא זה שעולה 50, ממש גזל , נותן ביצועים יותר טובים מקירורים של 500 ש"ח בארץ . עובר על מבחנים , לא בטוח שה 7600x3d שווה את המאמץ , עם כל האמפטיה לAMD , כאשר הכל מתומחר אותו דבר נראה שה 14700K הוא הבחירה הנכונה1 point
-
צודק טעות שלי . בכל מקרה, איך שאמרתי (ונסגרתי על זה עכשיו יותר..) אני מעדיף את TMS בגלל הפריסה שלהם . אצלם אין כמעט זיכרונות 2X64 . כך שאין בכלל זולים לצערי , אבל מצאתי אחד שהוא קצת פחות יקר במהירות 6000 וחברה אמינה . (חבל שאי אפשר להזמין מאמזון ולהגיד להם להרכיב) לגבי זה גם אתה צודק. החלפתי את הכוננים לדגם קצת יותר זול ועכשיו הפער לGEN4 של סמסונג כבר לא כזה גדול כך שאשאר עם GEN5. לגבי ספק אני מעדיף איכותי לשנים רבות ... נראה לי שזהו בעז"ה . זה מה שיצא : https://tms.co.il/builds/540393 נקווה לטוב1 point
-
לא מכיר אותם ולא כלום. אני מכיר את הנייד, לא את החנות ... :-) כל עוד הנייד באחריות יבואן רישמי, אין לחנות כמעט שום משמעות. דרך אגב, רצוי להרחיב את האחריות ל - 3 שנים. בקיצור, הדגש על הנייד, לא מי שמוכר אותו. אם חלילה תהיה בעיה, היבואן הוא הכתובת.1 point
-
1 point
-
להסתכל מהצד על הזבל הזה המתקרא מערכת הפעלה ועל הצרות שהוא גורם לעדר ולהתפלא כל פעם מחדש.1 point
-
1 pointשבוע טוב לכולם. מה דעתכם על זה - לאחרונה, ביתר שאת, ישנה תופעה של גולשים בכל מיני תחומים, כמו יעוץ לפני קניה, תקלות חומרה וכו' וכו' שפותחים דיון ו .... נעלמים. מי לשבוע, מי לחודש ומי בכלל. הדבר עוד יותר גרוע כאשר זה קורה אחרי שניתנות תשובות לפניה. אולי הגיע הזמן פשוט לחסום גולשים כאלה !1 point
-
על קצה המזלג - מעבדי אינטל בכלל לא עונים מבחינת NPU לתקן ה - AI של מיקרוסופט. כרגע, רק מעבדי AMD הם אלה שכן, כמו 365 וצפונה. מן הסתם, זה מה שצריך לחפש. רק שאלה, עיניך הרואות, לא כ"כ נמצאים בחנויות עם סניפים באילת ...1 point












.png.47f4912b054ca9021f6a2f39e73b8d79.png)